2026,
13(7):
1536-1557.
doi: 10.1109/JAS.2026.126050
Abstract:
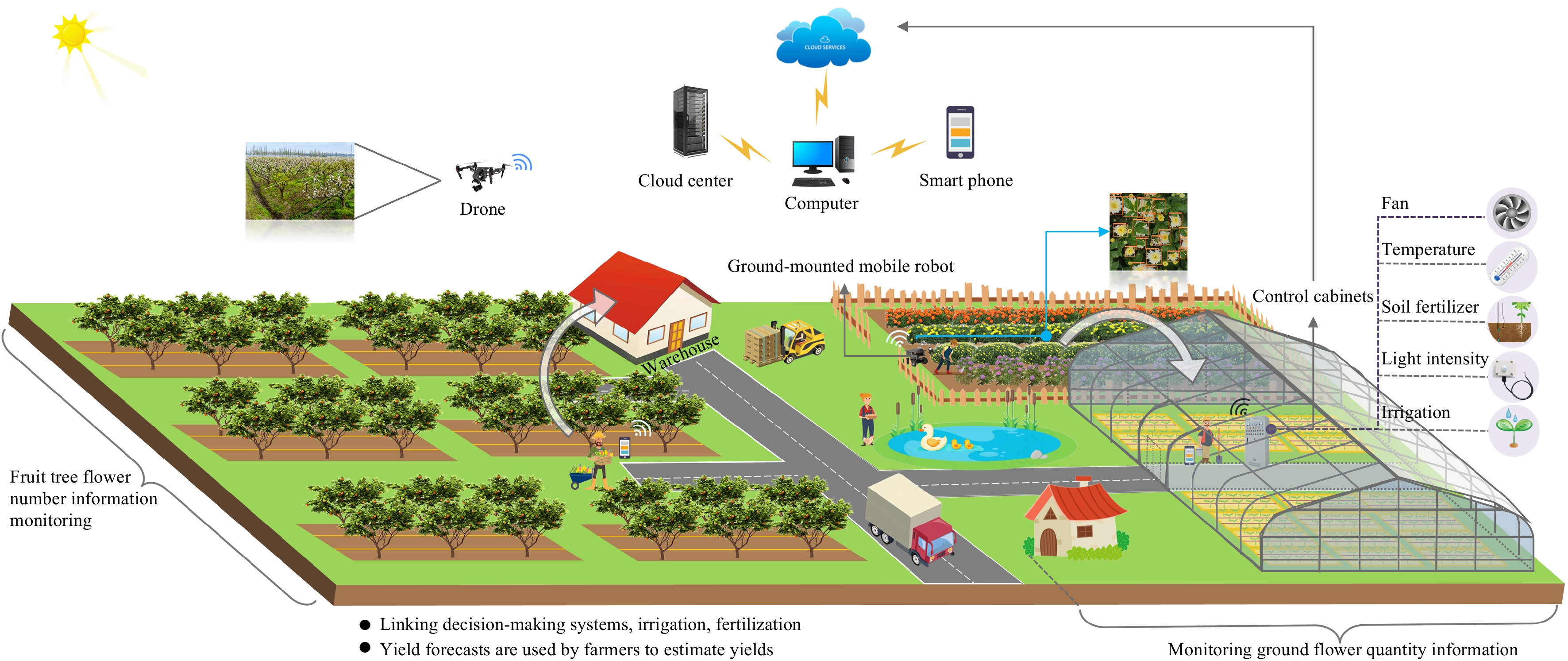
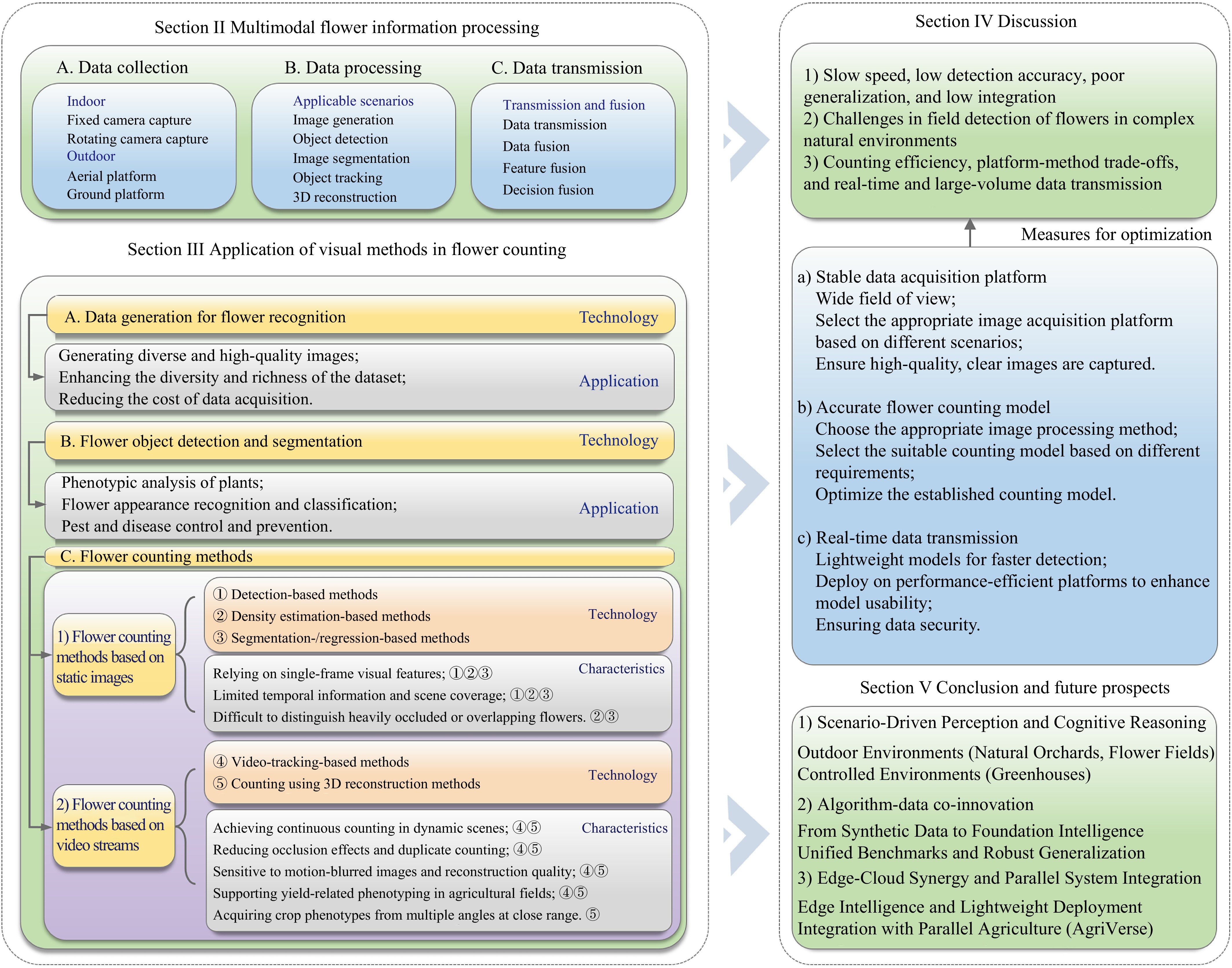
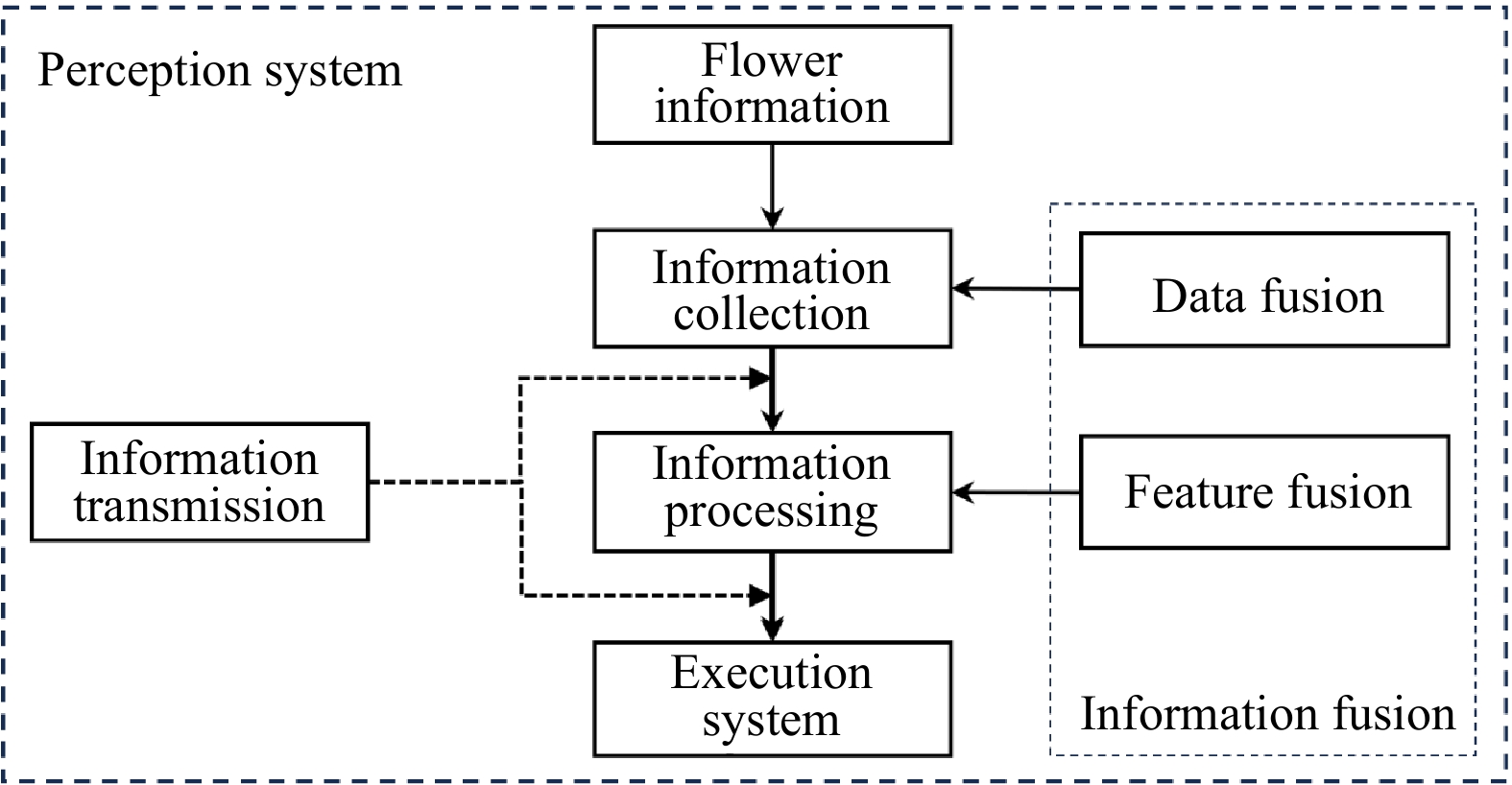
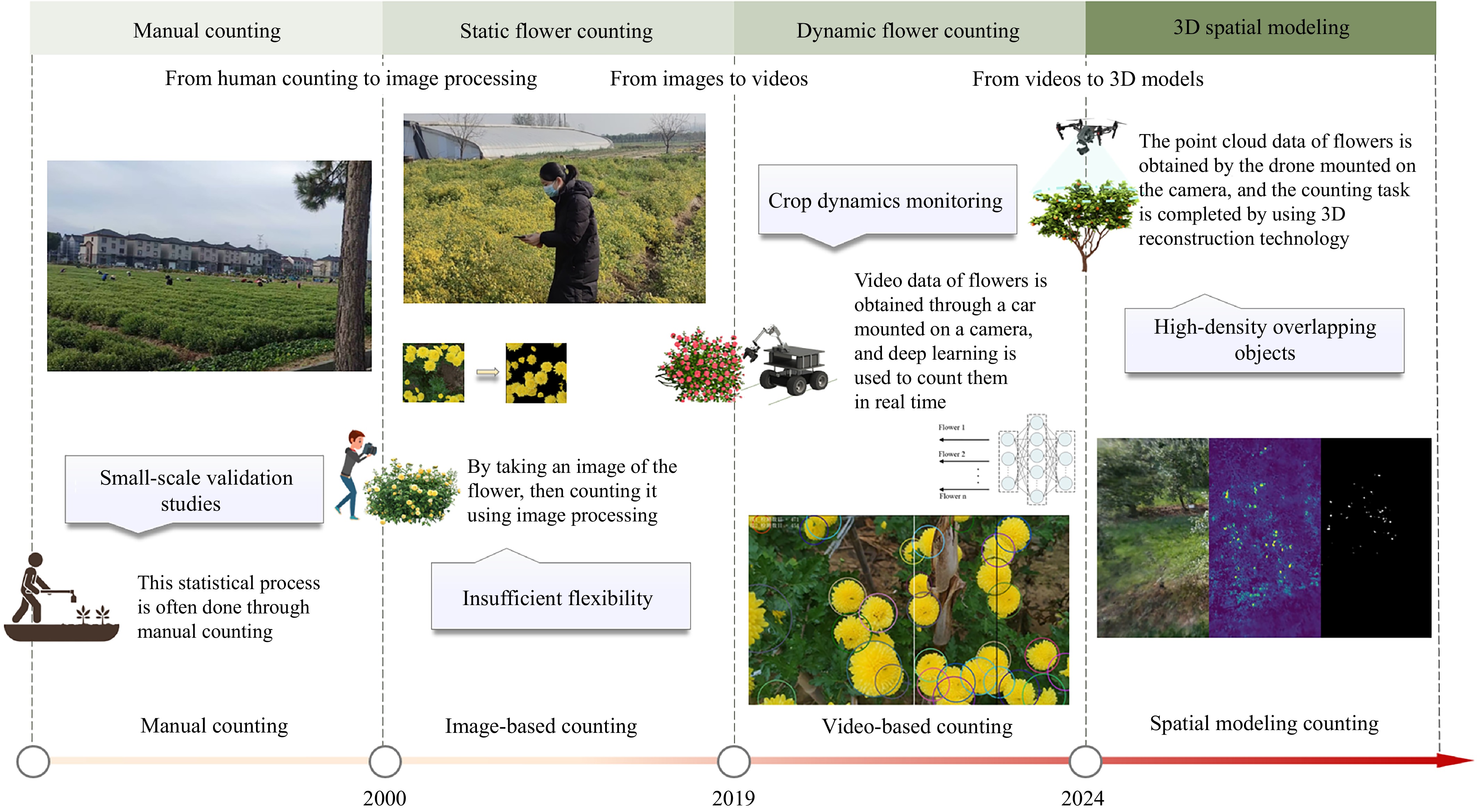
With the rapid integration of modern information technologies into agriculture, smart agriculture enables increasingly precise phenotyping and yield prediction. Flower counting is a key phenological indicator; however, achieving high precision remains a significant challenge due to severe occlusion, density variations, and environmental variability (e.g., lighting/weather). Moreover, existing studies remain fragmented without a comprehensive synthesis. To bridge this fundamental research gap, we present the first systematic survey of computer-vision-based flower counting. In this work, we propose a novel taxonomy that categorizes methods into static (single-image) and dynamic (video/multi-view) paradigms and elucidates their evolutionary trajectory. Unlike conventional reviews, we conduct a multi-scale evaluation encompassing both horizontal (methodological evolution from traditional to deep learning) and vertical (cross-species and scene-condition) performance analyses. Crucially, we validate representative algorithms on deployed platforms—UAV and ground robots—through engineering case studies that quantify real-world trade-offs (e.g., height-accuracy and latency-robustness). Finally, we discuss prevailing limitations and propose future directions, including graph-based reasoning and AgriVerse integration (i.e., agriculture-centric metaverse or digital twin ecosystems), establishing a foundational framework for both academic research and industrial deployment.
S. Zang, L. Shu, R. Han, X. Yang, G. Cielniak, and F. Zhang, “Visual-based flower counting: Techniques and applications,” IEEE/CAA J. Autom. Sinica, vol. 13, no. 7, pp. 1536–1557, Jul. 2026. doi: 10.1109/JAS.2026.126050.

















 E-mail Alert
E-mail Alert