, Available online , doi: 10.1109/JAS.2025.125843
Abstract:
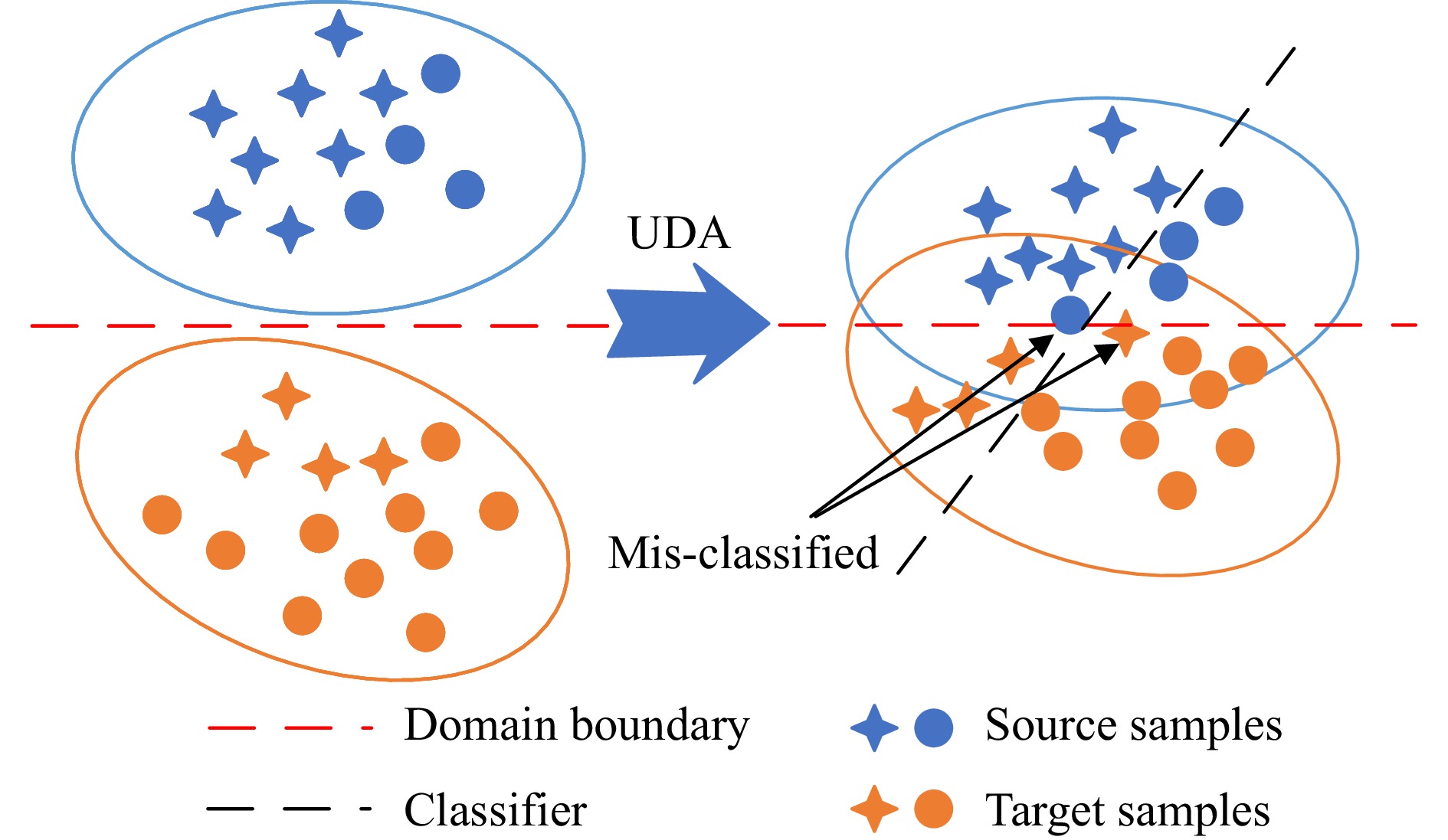
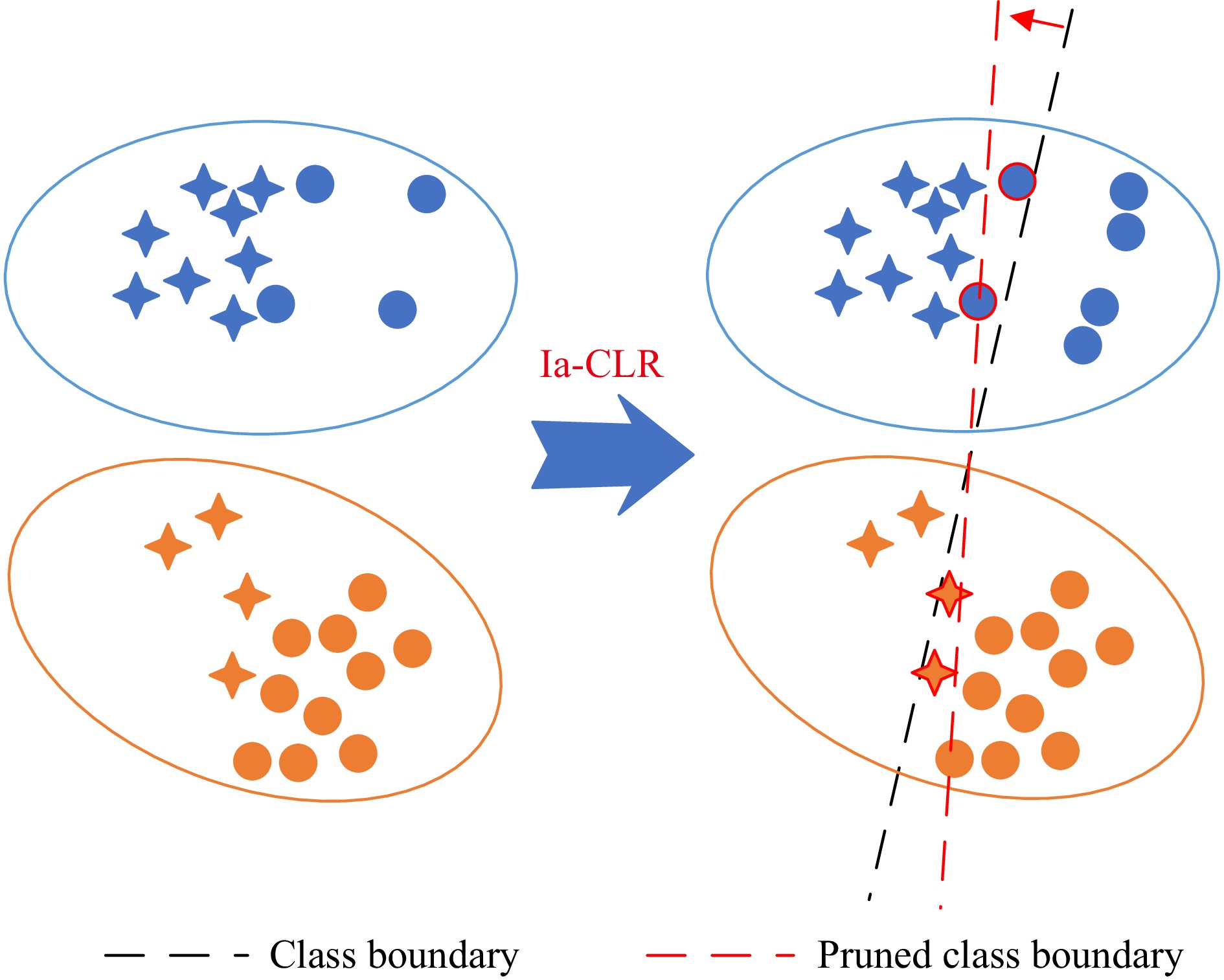
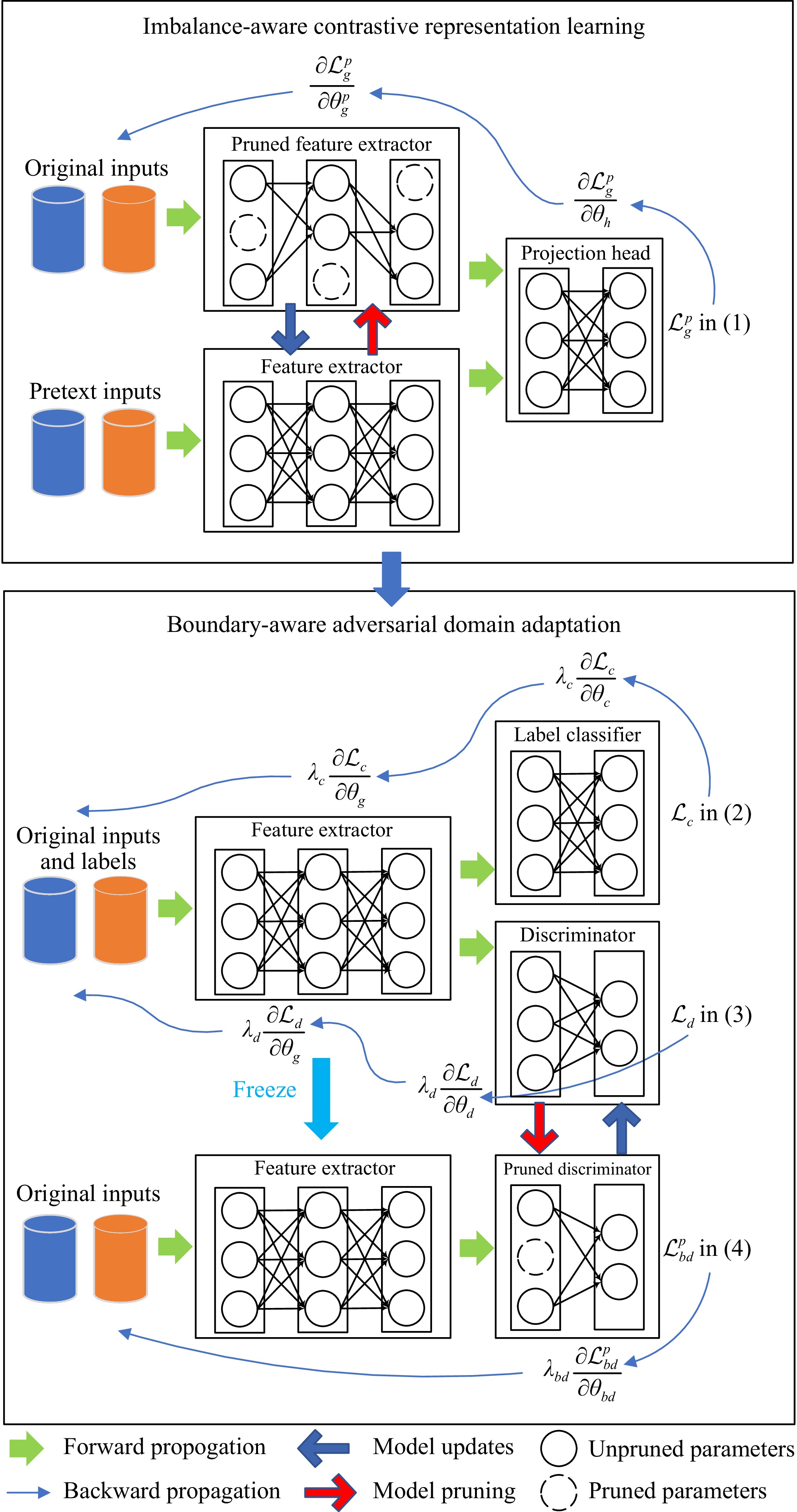
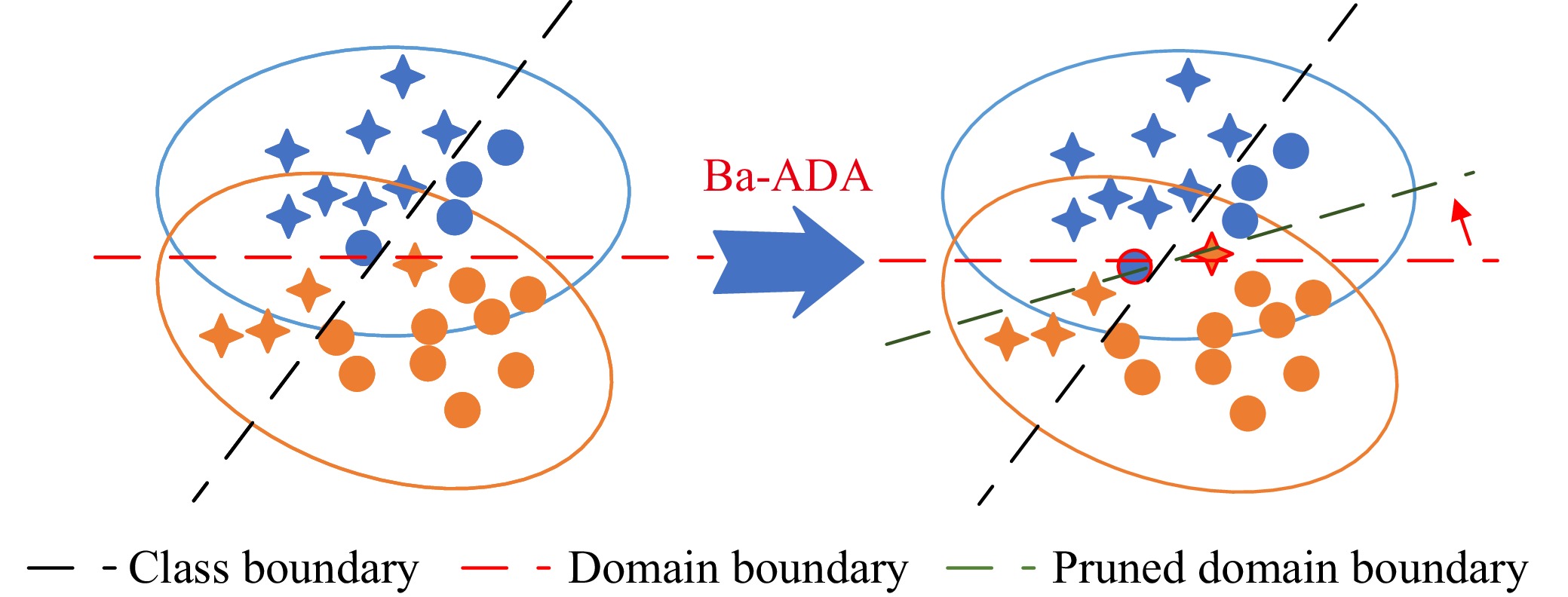
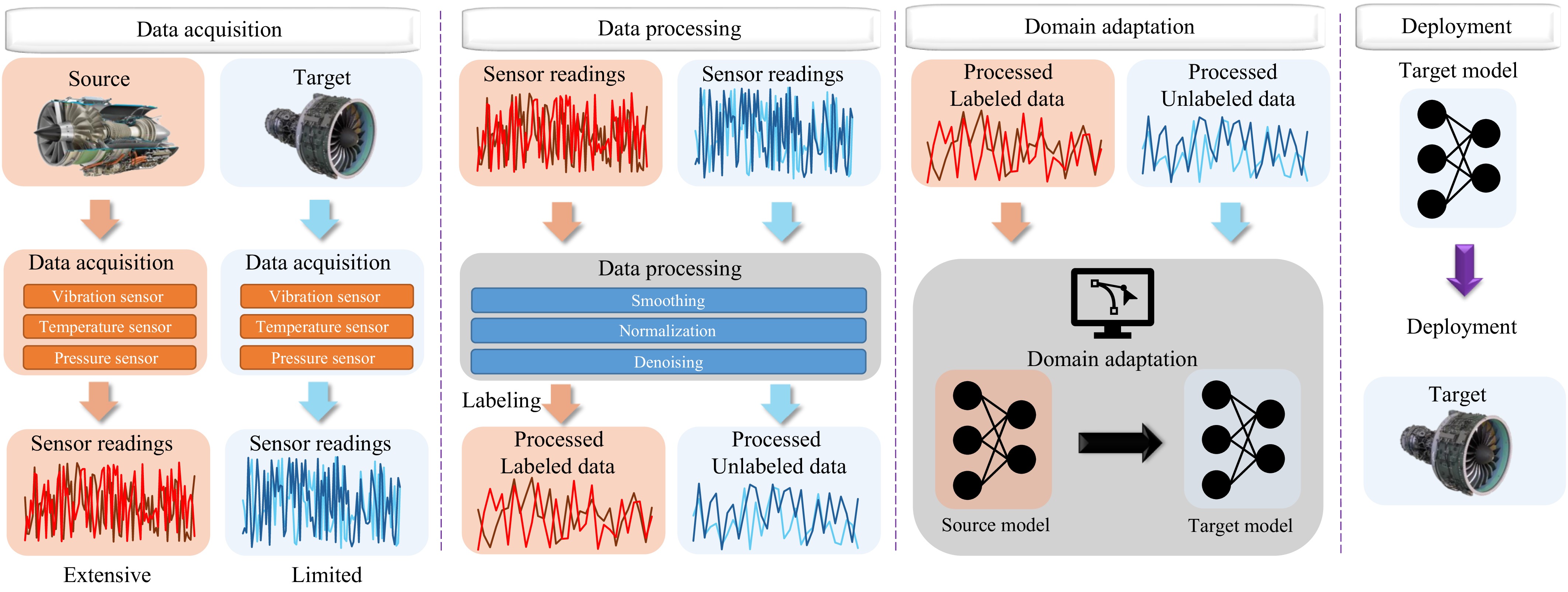
Remaining Useful Life (RUL) prediction for turbofan engines plays a vital role in predictive maintenance, ensuring operational safety and efficiency in aviation. Although data-driven approaches using machine learning and deep learning have shown potential, they face challenges such as limited data and distribution shifts caused by varying operating conditions. Domain Adaptation (DA) has emerged as a promising solution, enabling knowledge transfer from source domains with abundant data to target domains with scarce data while mitigating distributional shifts. Given the unique properties of turbofan engines—such as complex operating conditions, high-dimensional sensor data, and slower-changing signals—it is essential to conduct a focused review of DA techniques specifically tailored to turbofan engines. To address this need, this paper provides a comprehensive review of DA solutions for turbofan engine RUL prediction, analyzing key methodologies, challenges, and recent advancements. A novel taxonomy tailored to turbofan engines is introduced, organizing approaches into methodology-based (how DA is applied), alignment-based (where distributional shifts occur due to operational variations), and problem-based (why certain adaptations are needed to address specific challenges). This taxonomy offers a multidimensional view that goes beyond traditional classifications by accounting for the distinctive characteristics of turbofan engine data and the standard process of applying DA techniques to this area. Additionally, we evaluate selected DA techniques on turbofan engine datasets, providing practical insights for practitioners and identifying key challenges. Future research directions are identified to guide the development of more effective DA techniques, advancing the state of RUL prediction for turbofan engines.
Y. Wang, M. Ragab, Y. Hou, M. Wu, X. Li, and Z. Chen, “Deep domain adaptation for turbofan engine remaining useful life prediction: Methodologies, evaluation, and future trends,” IEEE/CAA J. Autom. Sinica, early access, 2026. doi: 10.1109/JAS.2025.125843.
















































 E-mail Alert
E-mail Alert


