A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 6
Volume 11
Issue 6
IEEE/CAA Journal of Automatica Sinica
| Citation: | Q. Ma, P. Jin, and F. L. Lewis, “Guaranteed cost attitude tracking control for uncertain quadrotor unmanned aerial vehicle under safety constraints,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 6, pp. 1447–1457, Jun. 2024. doi: 10.1109/JAS.2024.124317

|
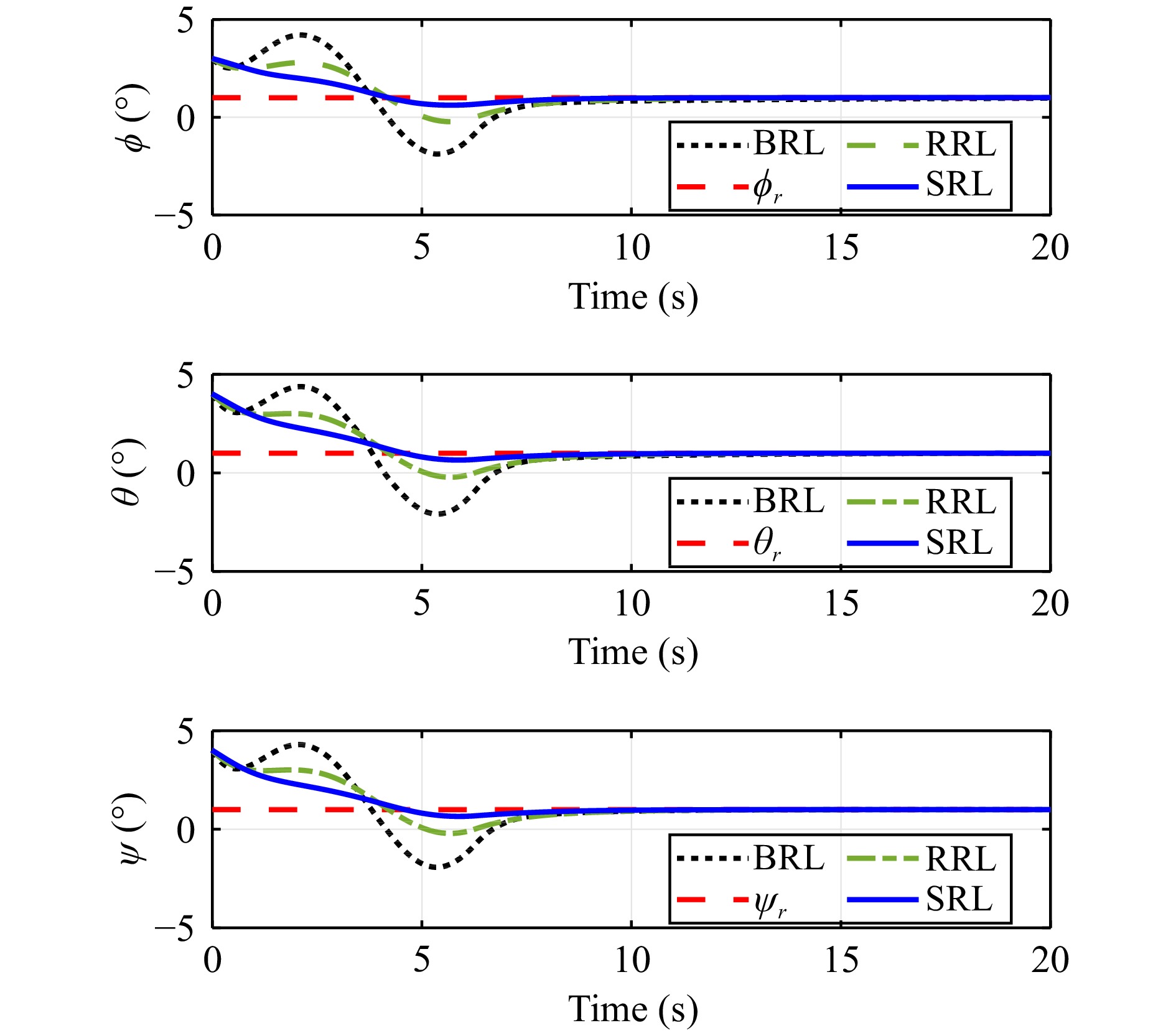
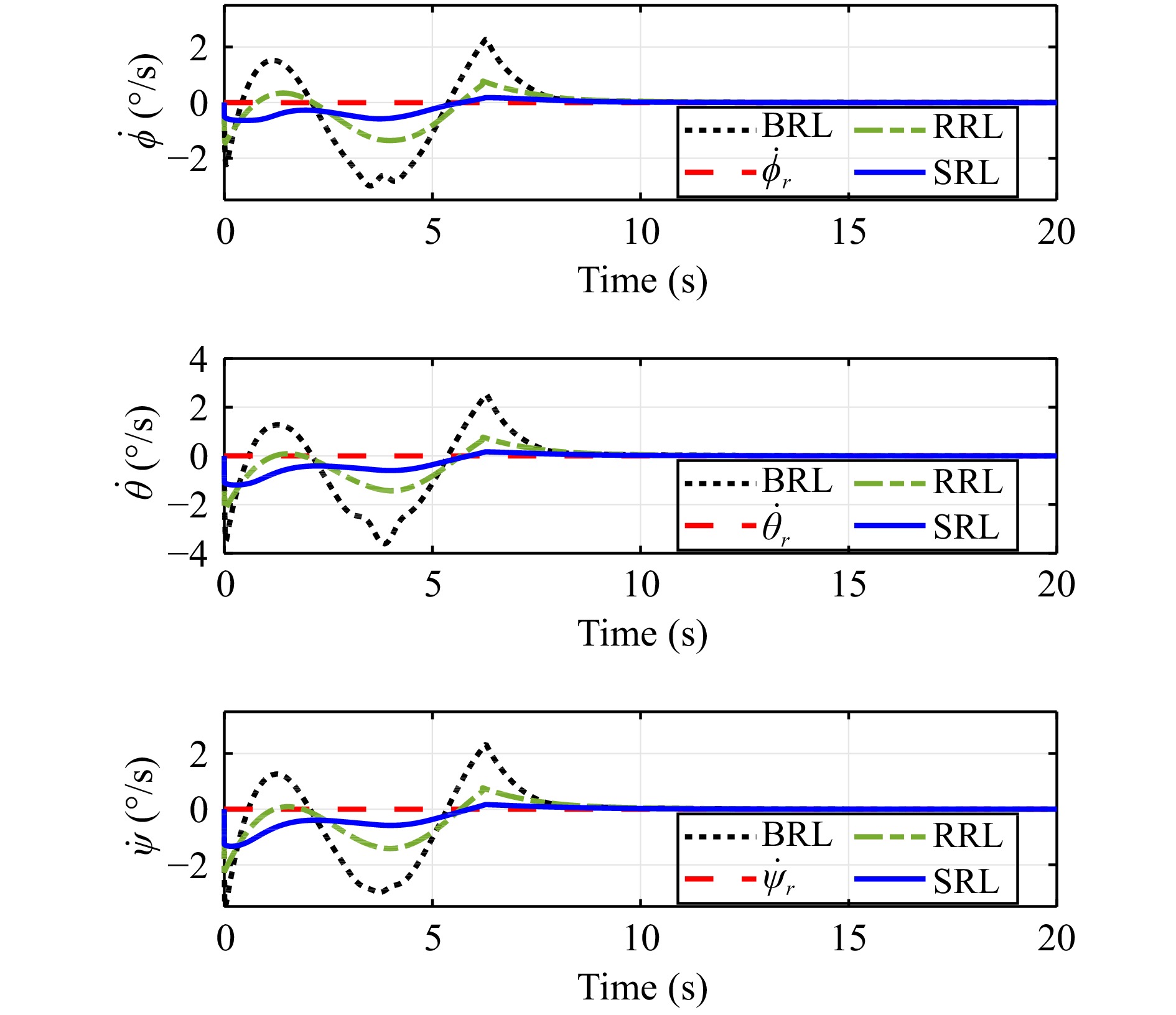
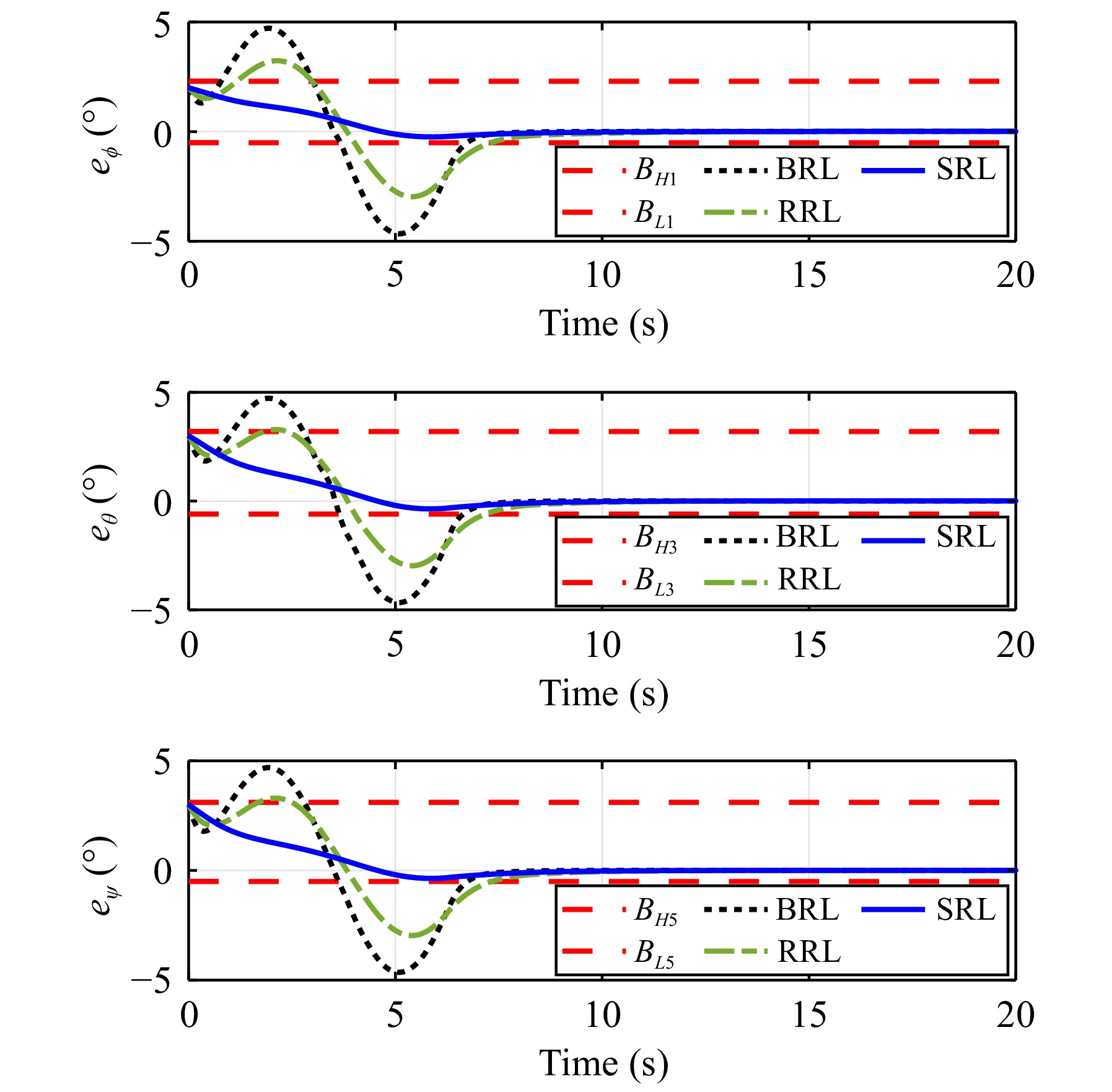
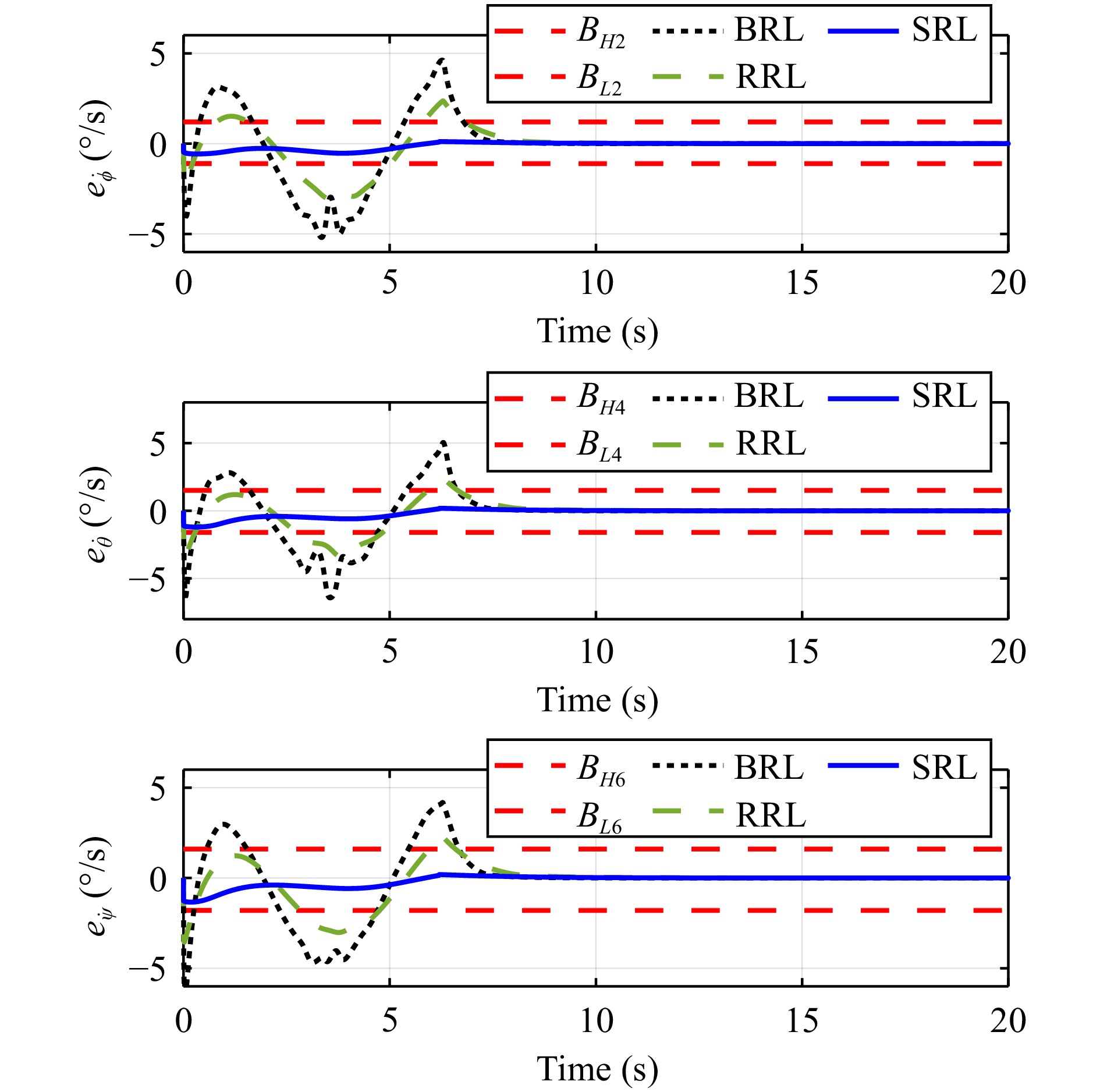
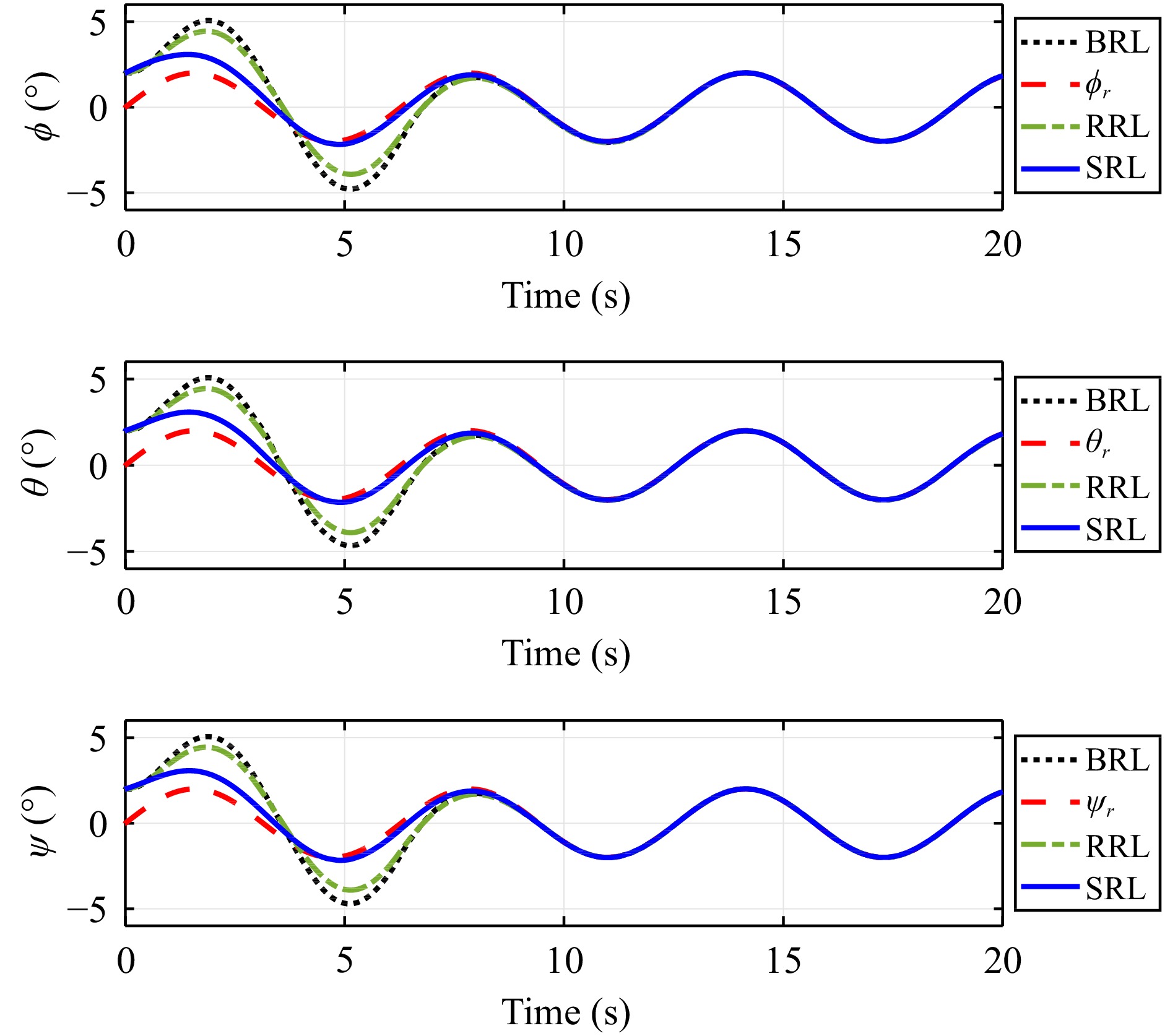
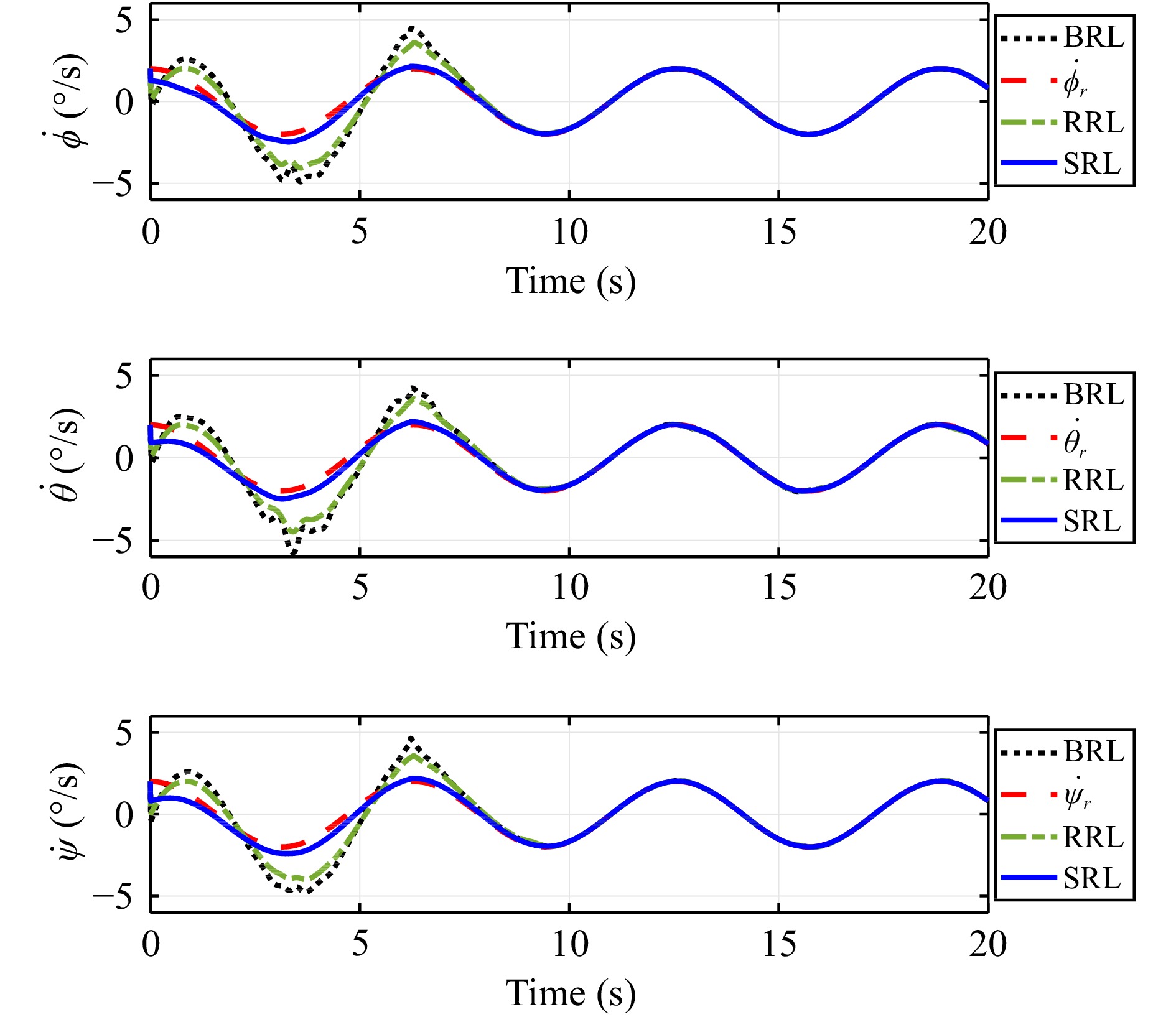
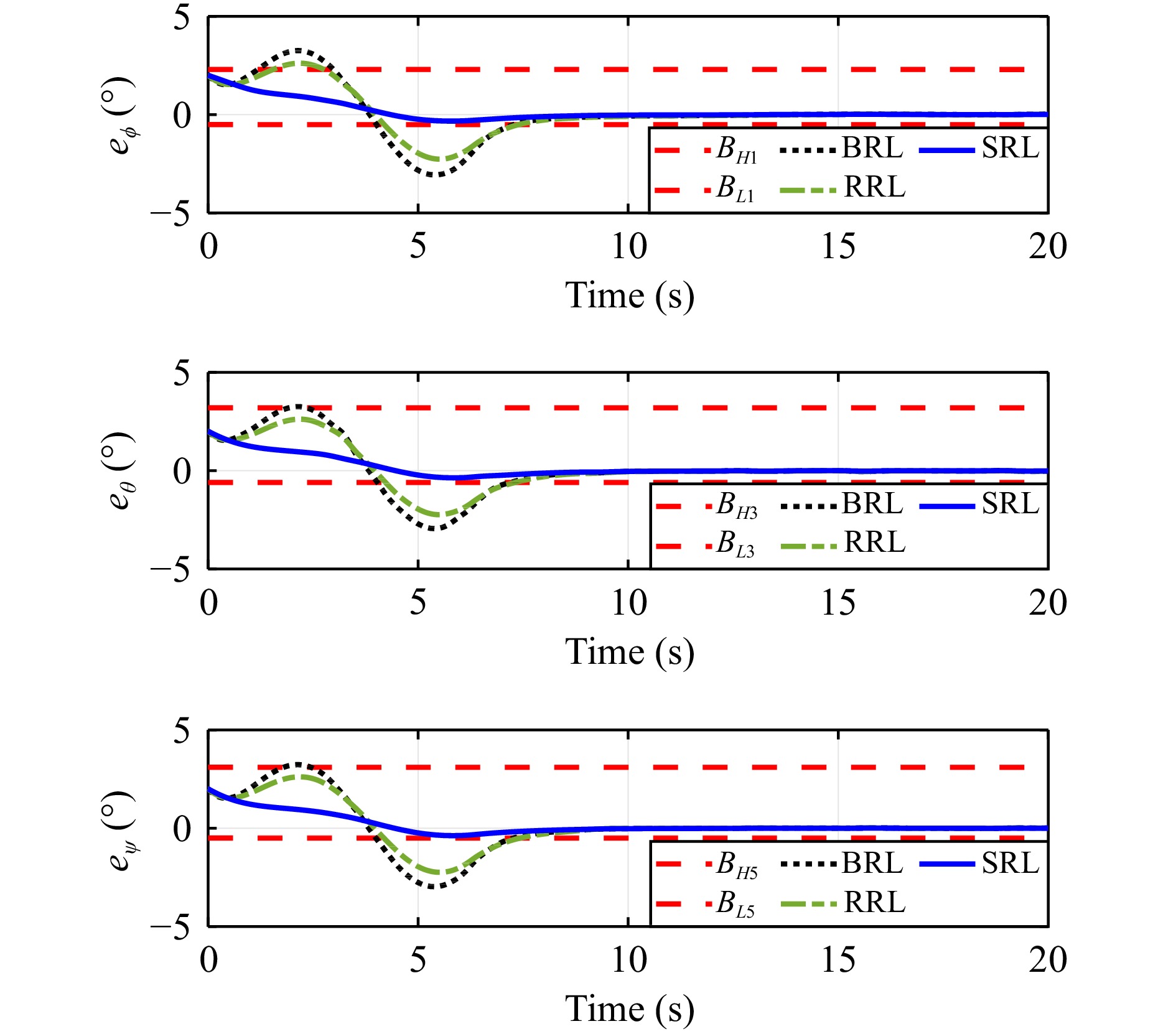
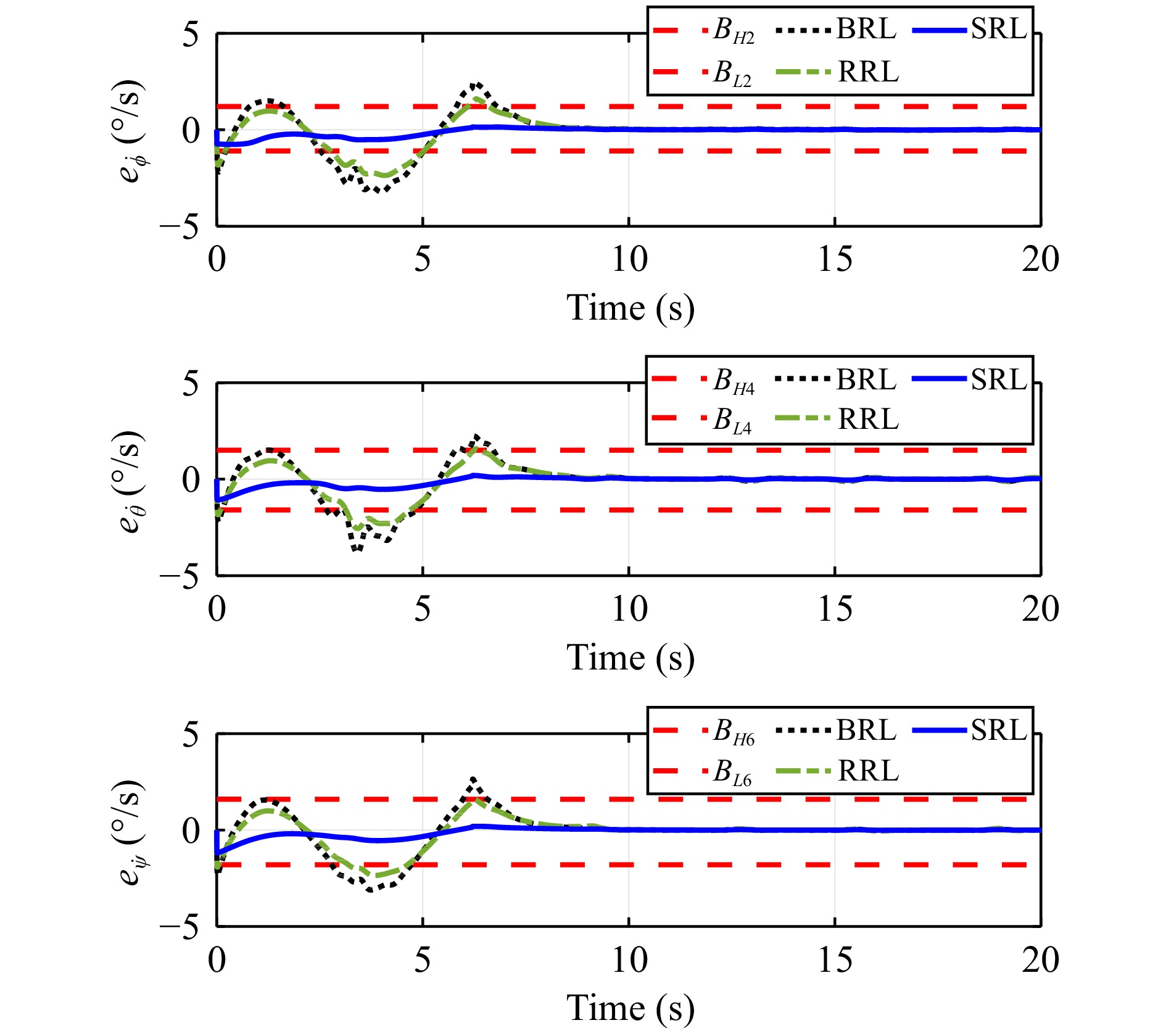
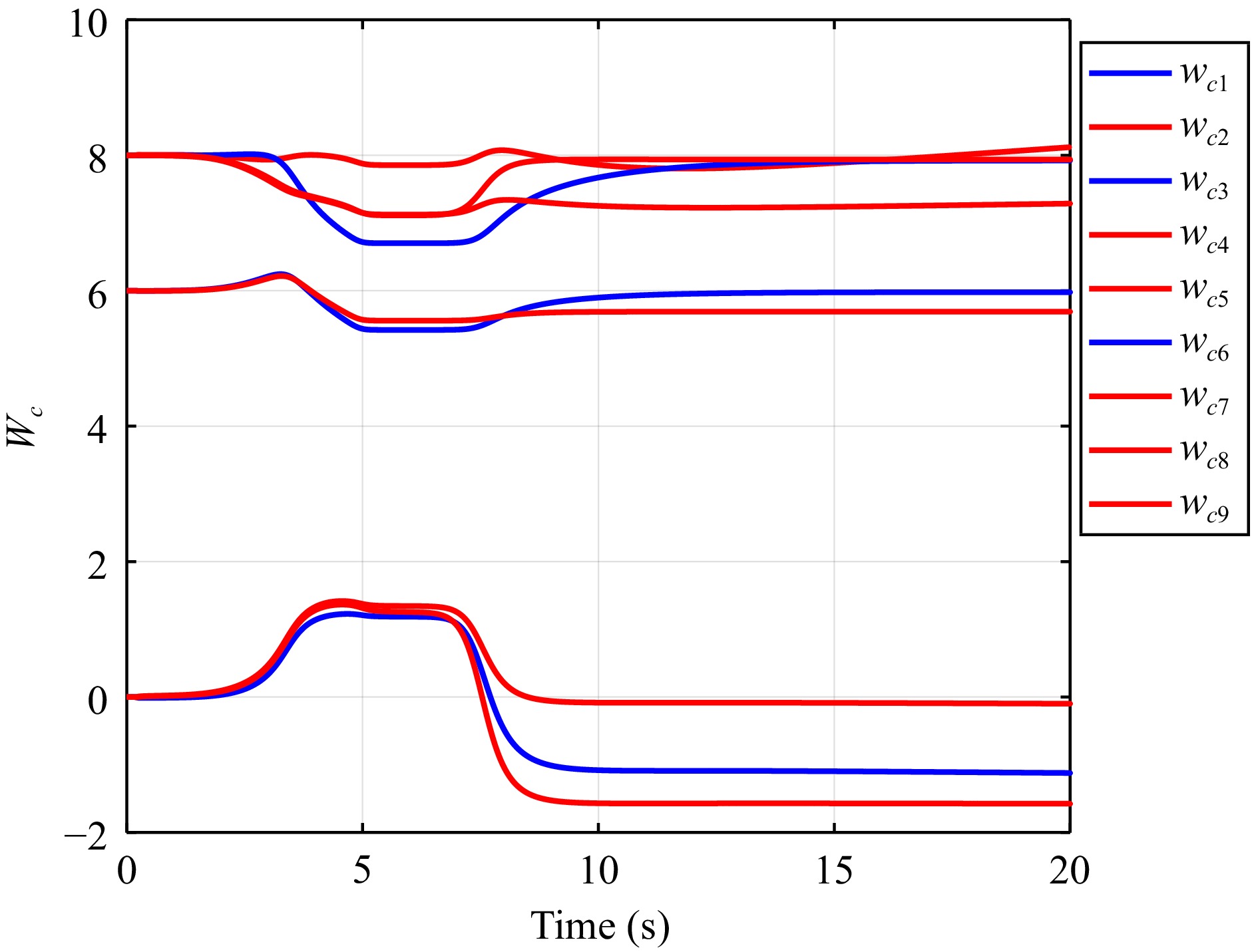
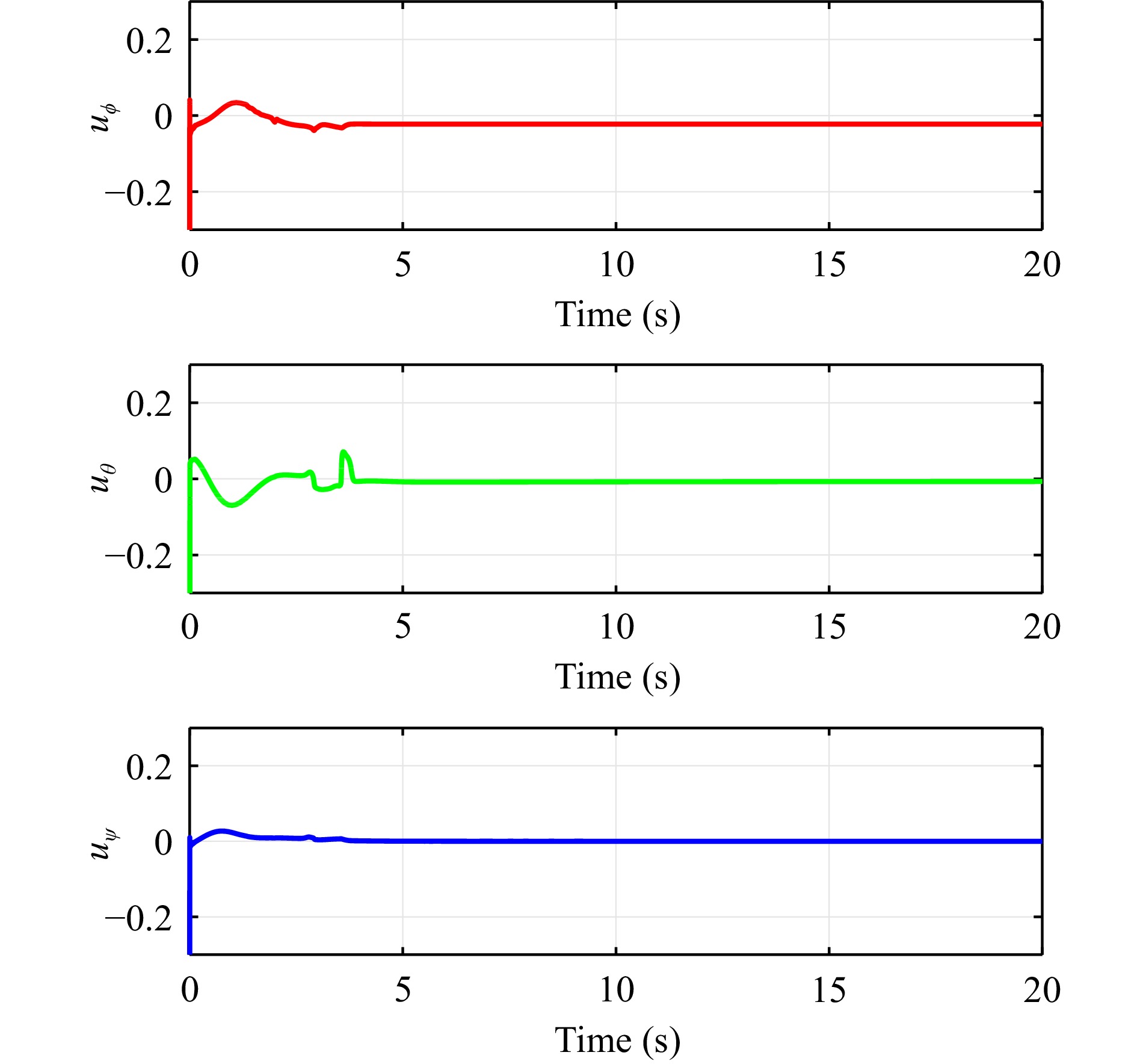
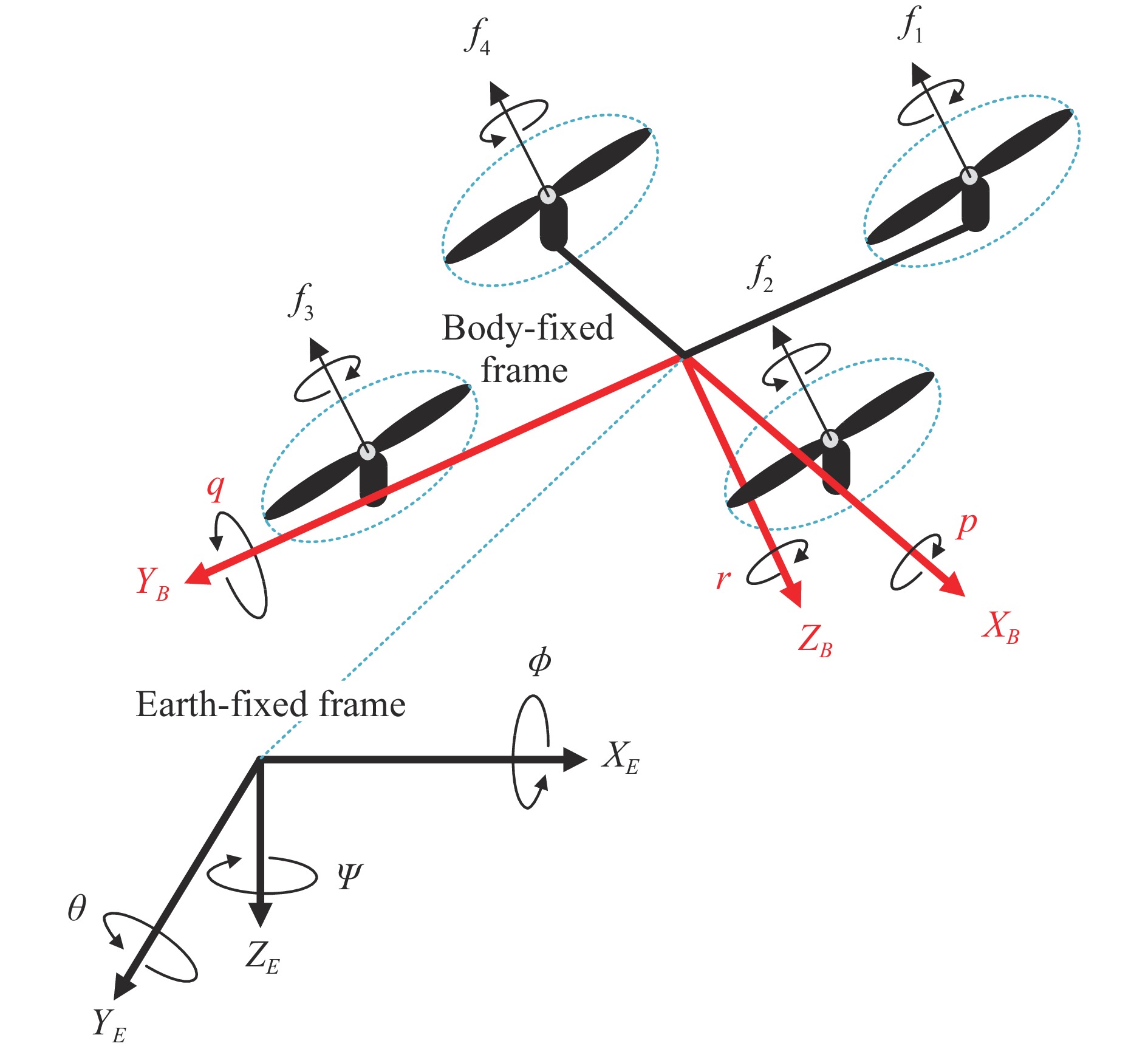
In this paper, guaranteed cost attitude tracking control for uncertain quadrotor unmanned aerial vehicle (QUAV) under safety constraints is studied. First, an augmented system is constructed by the tracking error system and reference system. This transformation aims to convert the tracking control problem into a stabilization control problem. Then, control barrier function and disturbance attenuation function are designed to characterize the violations of safety constraints and tolerance of uncertain disturbances, and they are incorporated into the reward function as penalty items. Based on the modified reward function, the problem is simplified as the optimal regulation problem of the nominal augmented system, and a new Hamilton-Jacobi-Bellman equation is developed. Finally, critic-only reinforcement learning algorithm with a concurrent learning technique is employed to solve the Hamilton-Jacobi-Bellman equation and obtain the optimal controller. The proposed algorithm can not only ensure the reward function within an upper bound in the presence of uncertain disturbances, but also enforce safety constraints. The performance of the algorithm is evaluated by the numerical simulation.

| [1] |
C. G. Mayhew, R. G. Sanfelice, and A. R. Teel, “Quaternion-based hybrid control for robust global attitude tracking,” IEEE Trans. Autom. Control, vol. 56, no. 11, pp. 2555–2566, Nov. 2011. doi: 10.1109/TAC.2011.2108490
|
| [2] |
W. Chen and Q. Hu, “Sliding-mode-based attitude tracking control of spacecraft under reaction wheel uncertainties,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 6, pp. 1475–1487, Jun. 2023. doi: 10.1109/JAS.2022.105665
|
| [3] |
Q. Chen, Y. Ye, Z. Hu, J. Na, and S. Wang, “Finite-time approximation-free attitude control of quadrotors: Theory and experiments,” IEEE Trans. Aerosp. Electron. Syst., vol. 57, no. 3, pp. 1780–1792, Jun. 2021. doi: 10.1109/TAES.2021.3050647
|
| [4] |
F. L. Lewis, D. Vrabie, and V. L. Syrmos. Optimal Control. New York, USA: Wiley, 2012.
|
| [5] |
G. Wen, W. Hao, W. Feng, and K. Gao, “Optimized backstepping tracking control using reinforcement learning for quadrotor unmanned aerial vehicle system,” IEEE Trans. Syst. Man,Cybern. Syst., vol. 52, no. 8, pp. 5004–5015, Aug. 2022. doi: 10.1109/TSMC.2021.3112688
|
| [6] |
S. Li, P. Durdevic, and Z. Yang, “Trajectory tracking of underactuated VTOL aerial vehicles with unknown system parameters via IRL,” IEEE Trans. Autom. Control, vol. 67, no. 6, pp. 3043–3050, Jun. 2022. doi: 10.1109/TAC.2021.3095031
|
| [7] |
C. Mu, Y. Zhang, G. Cai, R. Liu, and C. Sun, “A data-based feedback relearning algorithm for uncertain nonlinear systems,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1288–1303, May 2023. doi: 10.1109/JAS.2023.123186
|
| [8] |
M. Abu-Khalaf and F. L. Lewis, “Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach,” Automatica, vol. 41, no. 5, pp. 779–791, May 2005. doi: 10.1016/j.automatica.2004.11.034
|
| [9] |
H. Modares, F. L. Lewis, W. Kang, and A. Davoudi, “Optimal synchronization of heterogeneous nonlinear systems with unknown dynamics,” IEEE Trans. Autom. Control, vol. 63, no. 1, pp. 117–131, Jan. 2018. doi: 10.1109/TAC.2017.2713339
|
| [10] |
R. S. Sutton and A. G. Barto. Reinforcement Learning: An Introduction, 2nd ed. Cambridge, USA: MIT Press, 2017.
|
| [11] |
F. L. Lewis and D. Vrabie, “Reinforcement learning and adaptive dynamic programming for feedback control,” IEEE Circuits Syst. Mag., vol. 9, no. 3, pp. 683–710, Aug. 2009.
|
| [12] |
W. Gao, M. Mynuddin, D. C. Wunsch, and Z.-P. Jiang, “Reinforcement learning-based cooperative optimal output regulation via distributed adaptive internal model,” IEEE Trans. Neural Netw. Learn., vol. 33, no. 10, pp. 5229–5240, Oct. 2022. doi: 10.1109/TNNLS.2021.3069728
|
| [13] |
Y. Yang, Z. Ding, R. Wang, H. Modares, and D. C. Wunsch, “Data-driven human-robot interaction without velocity measurement using off-policy reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 47–63, Jan. 2022. doi: 10.1109/JAS.2021.1004258
|
| [14] |
W. Zhao, H. Liu, F. L. Lewis, and X. Wang, “Data-driven optimal formation control for quadrotor team with unknown dynamics,” IEEE Trans. Cybern., vol. 52, no. 8, pp. 7889–7898, Aug. 2022. doi: 10.1109/TCYB.2021.3049486
|
| [15] |
H. Liu, B. Li, B. Xiao, D. Ran, and C. Zhang, “Reinforcement learning-based tracking control for a quadrotor unmanned aerial vehicle under external disturbances,” Int. J. Robust Nonlinear Control, vol. 33, no. 17, pp. 10360–10377, Nov. 2023. doi: 10.1002/rnc.6334
|
| [16] |
O. Elhaki and K. Shojaei, “A novel model-free robust saturated reinforcement learning-based controller for quadrotors guaranteeing prescribed transient and steady state performance,” Aerosp. Sci. Technol., vol. 119, p. 107128, Dec. 2021. doi: 10.1016/j.ast.2021.107128
|
| [17] |
M. L. Greene, P. Deptula, S. Nivison, and W. E. Dixon, “Sparse learning-based approximate dynamic programming with barrier constraints,” IEEE Control Systems Letters, vol. 4, no. 3, pp. 743–748, Jul. 2020. doi: 10.1109/LCSYS.2020.2977927
|
| [18] |
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,” Annu. Rev. Control,Robot.,Auton. Syst., vol. 5, pp. 411–444, Jan. 2022. doi: 10.1146/annurev-control-042920-020211
|
| [19] |
Q. Zhang, W. Pan, and V. Reppa, “Model-reference reinforcement learning for collision-free tracking control of autonomous surface vehicles,” IEEE Trans. Intell. Transp. Syst., vol. 23, no. 7, pp. 8770–8781, Jul. 2022. doi: 10.1109/TITS.2021.3086033
|
| [20] |
Q. Hu, H. Yang, H. Dong, and X. Zhao, “Learning-based 6-DOF control for autonomous proximity operations under motion constraints,” IEEE Trans. Aerosp. Electron. Syst., vol. 57, no. 6, pp. 4097–4109, Dec. 2021. doi: 10.1109/TAES.2021.3094628
|
| [21] |
H. Dong, X. Zhao, and H. Yang, “Reinforcement learning-based approximate optimal control for attitude reorientation under state constraints,” IEEE Trans. Control Syst. Technol., vol. 29, no. 4, pp. 1664–1673, Jul. 2021. doi: 10.1109/TCST.2020.3007401
|
| [22] |
H. Yang, Q. Hu, H. Dong, and X. Zhao, “ADP-based spacecraft attitude control under actuator misalignment and pointing constraints,” IEEE Trans. Ind. Electron., vol. 69, no. 9, pp. 9342–9352, Sept. 2022. doi: 10.1109/TIE.2021.3116571
|
| [23] |
Y. Guo, G. Chen, and T. Zhao, “Learning-based collision-free coordination for a team of uncertain quadrotor UAVs,” Aerosp. Sci. Technol., vol. 119, p. 107127, Dec. 2021. doi: 10.1016/j.ast.2021.107127
|
| [24] |
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs for safety critical systems,” IEEE Trans. Autom. Control, vol. 62, no. 8, pp. 3861–3876, Dec. 2017. doi: 10.1109/TAC.2016.2638961
|
| [25] |
F. Blanchini, “Set invariance in control,” Automatica, vol. 35, no. 11, pp. 1747–1767, Nov. 1999. doi: 10.1016/S0005-1098(99)00113-2
|
| [26] |
Q. Meng, Q. Ma, and Y. Shi, “Adaptive fixed-time stabilization for a class of uncertain nonlinear systems,” IEEE Trans. Autom. Control, vol. 68, no. 11, pp. 6929–6936, Nov. 2023. doi: 10.1109/TAC.2023.3244151
|
| [27] |
Z. Marvi and B. Kiumarsi, “Safe reinforcement learning: A control barrier function optimization approach,” Int. J. Robust Nonlinear Control, vol. 31, no. 6, pp. 1923–1940, Apr. 2021. doi: 10.1002/rnc.5132
|
| [28] |
N. M. T. Kokolakis and K. G.Vamvoudakis, “Safety-aware pursuit-evasion games in unknown environments using Gaussian processes and finite-time convergent reinforcement learning,” IEEE Trans. Neural Netw. Learn., vol. 35, no. 3, pp. 3130–3143, Mar. 2024. doi: 10.1109/TNNLS.2022.3203977
|
| [29] |
D. Liu, D. Wang, F. Wang, H. Li, and X. Yang, “Neural-network-based online HJB solution for optimal robust guaranteed cost control of continuous-time uncertain nonlinear systems,” IEEE Trans. Cybern., vol. 44, no. 12, pp. 2834–2847, Dec. 2014. doi: 10.1109/TCYB.2014.2357896
|
| [30] |
H. Zhang, Y. Liang, H. Su, and C. Liu, “Event-driven guaranteed cost control design for nonlinear systems with actuator faults via reinforcement learning algorithm,” IEEE Trans. Syst. Man,Cybern. Syst., vol. 50, no. 11, pp. 4135–4150, Nov. 2019.
|
| [31] |
D. Wang, J. Qiao, and L. Cheng, “An approximate neuro-optimal solution of discounted guaranteed cost control design,” IEEE Trans. Cybern., vol. 52, no. 1, pp. 77–86, Jan. 2022. doi: 10.1109/TCYB.2020.2977318
|
| [32] |
C. Mu and Y. Zhang, “Learning-based robust tracking control of quadrotor with time-varying and coupling uncertainties,” IEEE Trans. Neural Netw. Learn., vol. 31, no. 1, pp. 259–273, Jan. 2019.
|
| [33] |
W. Zhao, H. Liu, and F. L. Lewis, “Data-driven fault-tolerant control for attitude synchronization of nonlinear quadrotors,” IEEE Trans. Autom. Control, vol. 66, no. 11, pp. 5584–5591, Nov. 2021. doi: 10.1109/TAC.2021.3053194
|
| [34] |
G. V. Raffo, M. G. Ortega, and F. R. Rubio, “An integral predictive/nonlinear H∞ control structure for a quadrotor helicopter,” Automatica, vol. 46, no. 1, pp. 29–39, Jan. 2010. doi: 10.1016/j.automatica.2009.10.018
|
| [35] |
K. P. Tee, S. S. Ge, and E. H. Tay, “Barrier Lyapunov functions for the control of output-constrained nonlinear systems,” Automatica, vol. 45, no. 4, pp. 918–927, Dec. 2009. doi: 10.1016/j.automatica.2008.11.017
|
| [36] |
Z. Zheng, Y. Huang, L. Xie, and B. Zhu, “Adaptive trajectory tracking control of a fully actuated surface vessel with asymmetrically constrained input and output,” IEEE Trans. Control Syst. Technol., vol. 26, no. 5, pp. 1851–1859, Sept. 2018. doi: 10.1109/TCST.2017.2728518
|
| [37] |
K. G. Vamvoudakis, M. F. Miranda, and J. P. Hespanha, “Asymptotically stable adaptive-optimal control algorithm with saturating actuators and relaxed persistence of excitation,” IEEE Trans. Neural Netw. Learn., vol. 27, no. 11, pp. 2386–2398, Oct. 2015.
|
| [38] |
X. Yang, M. Xu, and Q. Wei, “Dynamic event-sampled control of interconnected nonlinear systems using reinforcement learning,” IEEE Trans. Neural Netw. Learn., vol. 35, no. 1, pp. 923–937, Jan. 2024. doi: 10.1109/TNNLS.2022.3178017
|
| [39] |
K. G. Vamvoudakis and F. L. Lewis, “Online actor-critic algorithm to solve the continuous-time infinite horizon optimal control problem,” Automatica, vol. 46, no. 5, pp. 878–888, Nov. 2010. doi: 10.1016/j.automatica.2010.02.018
|
| [40] |
N. Wang, Y. Gao, H. Zhao, and C. K. Ahn, “Reinforcement learning-based optimal tracking control of an unknown unmanned surface vehicle,” IEEE Trans. Neural Netw. Learn., vol. 32, no. 7, pp. 3034–3045, Jul. 2021. doi: 10.1109/TNNLS.2020.3009214
|
Figures(11)






 DownLoad:
DownLoad: