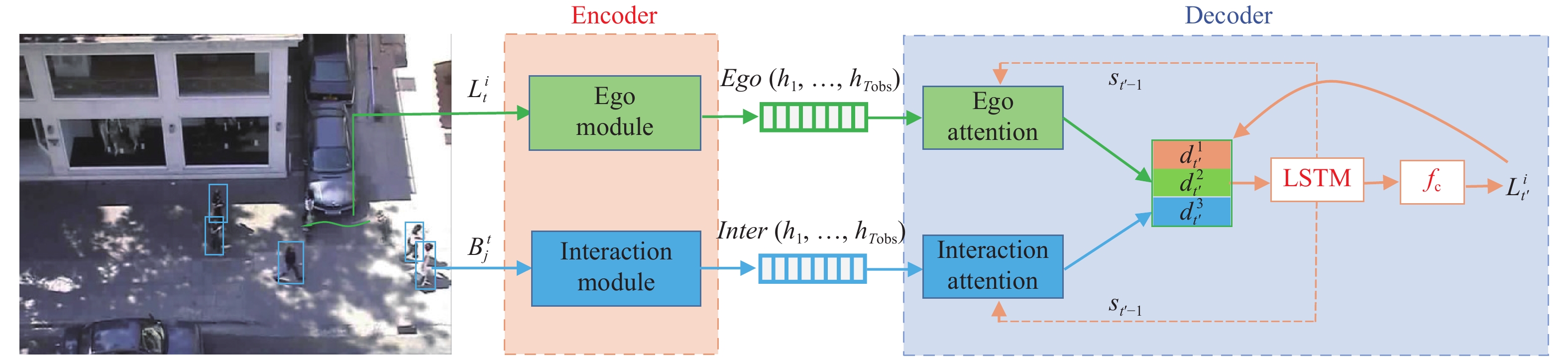
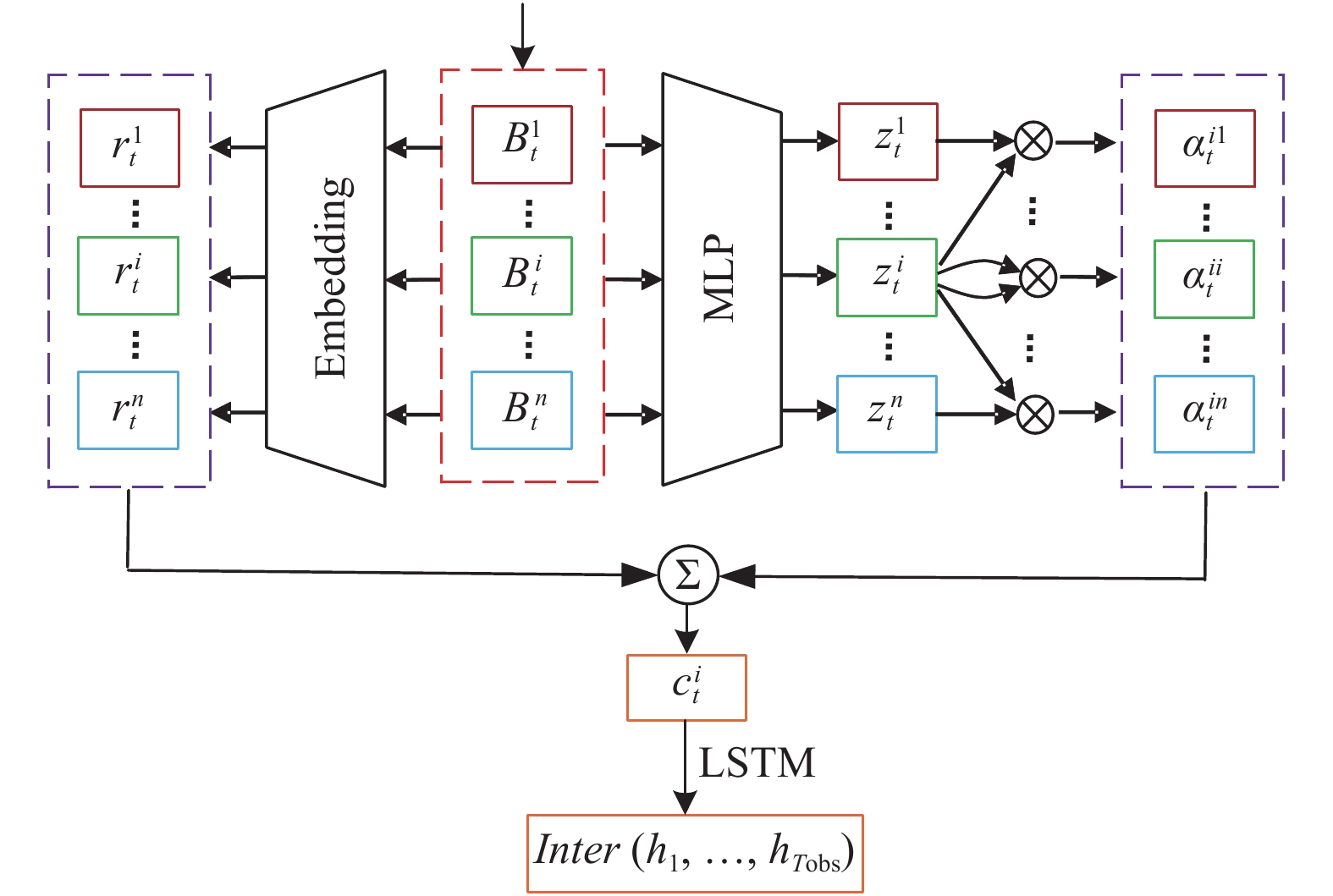
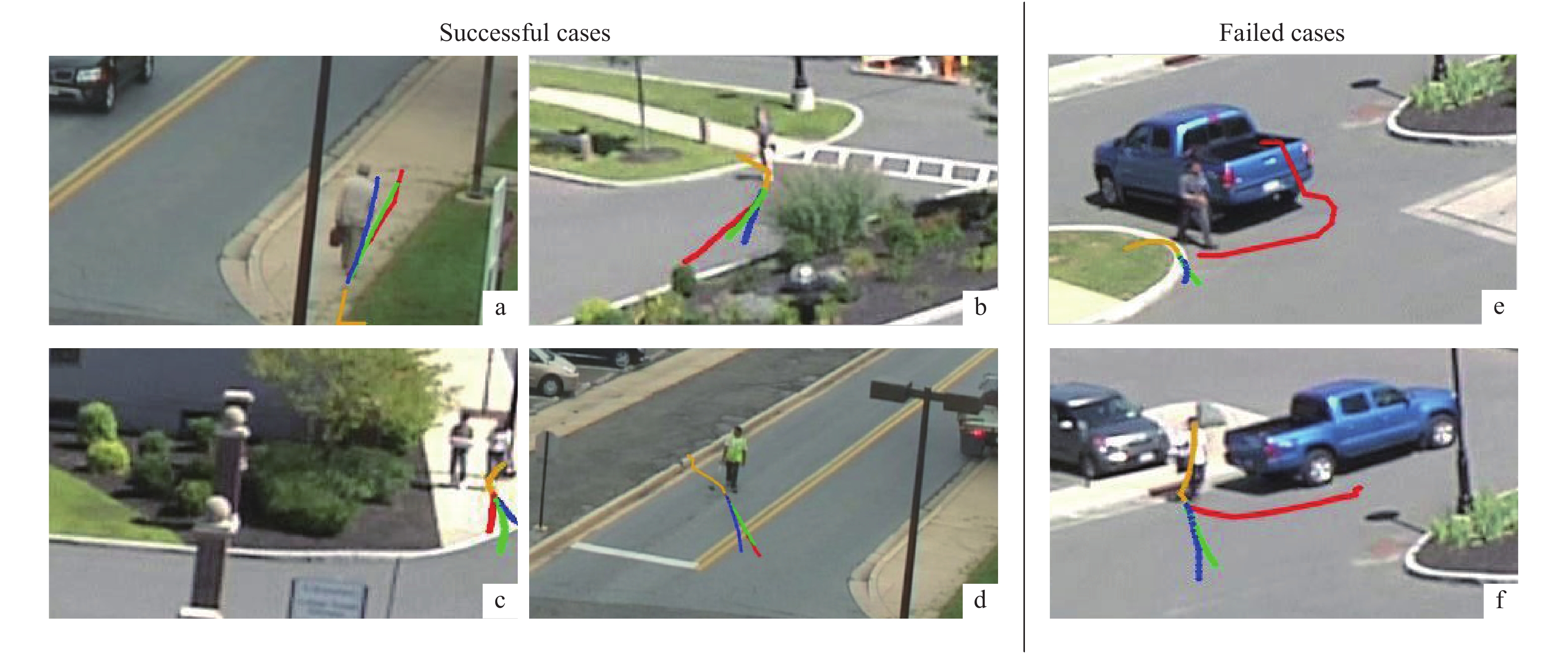
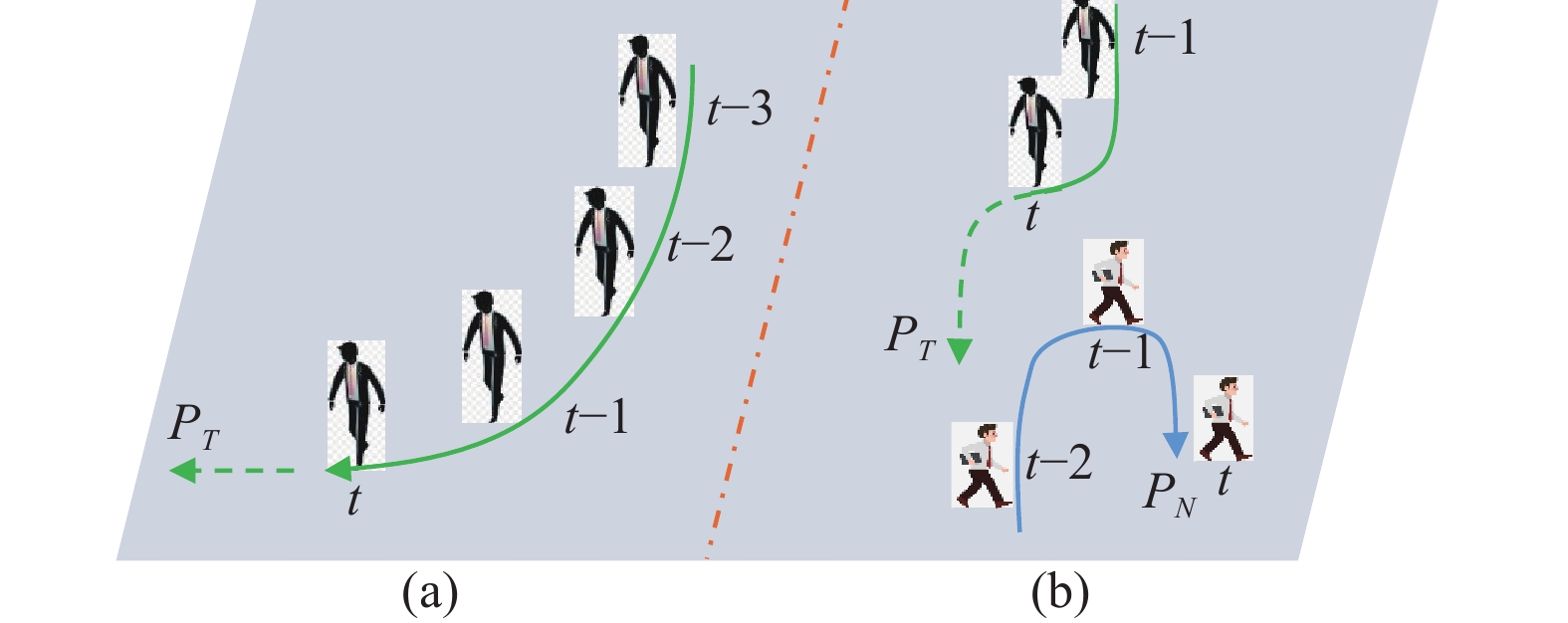
A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 7
Issue 4
Volume 7
Issue 4
IEEE/CAA Journal of Automatica Sinica
| Citation: | Xiaodong Zhao, Yaran Chen, Jin Guo and Dongbin Zhao, "A Spatial-Temporal Attention Model for Human Trajectory Prediction," IEEE/CAA J. Autom. Sinica, vol. 7, no. 4, pp. 965-974, July 2020. doi: 10.1109/JAS.2020.1003228

|

| [1] |
L. Lv, D. B. Zhao, and Q. Q. Deng, “A semi-supervised predictive sparse decomposition based on task-driven dictionary learning,” Cognitive Computation, vol. 9, no. 1, pp. 1–10, 2017.
|
| [2] |
D. B. Zhao, Z. H. Hu, Z. P. Xia, C. Alippi, Y. H. Zhu, and D. Wang, “Fullrange adaptive cruise control based on supervised adaptive dynamic programming,” Neurocomputing, vol. 125, pp. 57–67, 2014. doi: 10.1016/j.neucom.2012.09.034
|
| [3] |
D. Li, D. B. Zhao, Q. C. Zhang, and Y. R. Chen, “Reinforcement learning and deep learning based lateral control for autonomous driving,” IEEE Computational Intelligence Magazine, vol. 14, no. 2, pp. 83–98, 2019.
|
| [4] |
D. Li, Q. C. Zhang, D. B. Zhao, Y. Z. Zhuang, B. Wang, W. Liu, R. Tutunov, and J. Wang, “Graph attention memory for visual navigation,” arXiv preprint arXiv: 1905.13315, 2019.
|
| [5] |
T. Yagi, K. Mangalam, R. Yonetani, and Y. Sato, “Future person localization in first-person videos,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, 2018, pp. 7593–7602.
|
| [6] |
D. Makris and T. Ellis, “Path detection in video surveillance,” Image and Vision Computing, vol. 20, no. 12, pp. 895–903, 2002. doi: 10.1016/S0262-8856(02)00098-7
|
| [7] |
Y. R. Chen, D. B. Zhao, L. Lv, and Q. C. Zhang, “Multi-task learning for dangerous object detection in autonomous driving,” Information Sciences, vol. 432, pp. 559–571, 2018. doi: 10.1016/j.ins.2017.08.035
|
| [8] |
D. B. Zhao, Y. R. Chen, and L. Lv, “Deep reinforcement learning with visual attention for vehicle classification,” IEEE Trans. Cognitive and Developmental Systems, vol. 9, no. 4, pp. 356–367, 2017. doi: 10.1109/TCDS.2016.2614675
|
| [9] |
A. Alahi, K. Goel, V. Ramanathan, A. Robicquet, F. F. Li, and S. Savarese, “Social LSTM: Human trajectory prediction in crowded spaces,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, 2016, pp. 961–971.
|
| [10] |
A. Gupta, J. Johnson, F. F. Li, S. Savarese, and A. Alahi, “Social GAN: Socially acceptable trajectories with generative adversarial networks,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, 2018, pp. 2255–2264.
|
| [11] |
J. Chen, J. Liu, J. W. Liang, T. Y. Hu, W. Ke, W. Barrios, D. Huang, and A. G. Hauptmann, “Minding the gaps in a video action analysis pipeline,” in Proc. IEEE Winter Applications of Computer Vision Workshops. IEEE, 2019, pp. 41–46.
|
| [12] |
S. Pellegrini, A. Ess, and L. Van Gool, “Improving data association by joint modeling of pedestrian trajectories and groupings,” in Proc. European Conf. Computer Vision. Springer, 2010, pp. 452–465.
|
| [13] |
A. Lerner, Y. Chrysanthou, and D. Lischinski, “Crowds by example,” Computer Graphics Forum, vol. 36, no. 3, pp. 655–664, 2007.
|
| [14] |
G. Awad, A. Butt, K. Curtis, J. Fiscus, A. Godil, A. F. Smeaton, Y. Graham, W. Kraaij, G. Qunot, J. Magalhaes, D. Semedo, and S. Blasi, “Trecvid 2018: Benchmarking video activity detection, video captioning and matching, video storytelling linking and video search,” in TRECVID. 2018.
|
| [15] |
G. G. Qu and D. Shen, “Stochastic iterative learning control with faded signals,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 5, pp. 1196–1208, 2019. doi: 10.1109/JAS.2019.1911696
|
| [16] |
Y. R. Chen, D. B. Zhao, and H. R. Li, “Deep Kalman filter with optical flow for multiple object tracking,” in IEEE Int. Conf. Systems, Man, and Cybernetics. Bari, Italy: IEEE, Oct. 2019. pp. 3036–3041.
|
| [17] |
C. K. I. Williams, “Prediction with Gaussian processes: From linear regression to linear prediction and beyond,” in Nato Advanced Study Institute on Learning in Graphical Models. Springer, 1998, pp. 599–621.
|
| [18] |
D. Helbing and P. Molnár, “Social force model for pedestrian dynamics,” Physical Review E, vol. 51, no. 5, pp. 4282–4286, 1995. doi: 10.1103/PhysRevE.51.4282
|
| [19] |
A. Johansson, D. Helbing, and P. K. Shukla, “Specification of the social force pedestrian model by evolutionary adjustment to video tracking data,” Advances in Complex Systems, vol. 10, no. supp02, pp. 271–288, 2007. doi: 10.1142/S0219525907001355
|
| [20] |
H. Su, Y. R. Chen, S. W. Tong, and D. B. Zhao, “Real-time multiple object tracking based on optical flow,” in Proc. 9th Int. Conf. Information Science and Technology. IEEE, 2019. PP. 350–356.
|
| [21] |
S. Yi, H. S. Li, and X. G. Wang, “Pedestrian behavior understanding and prediction with deep neural networks,” in Proc. European Conf. Computer Vision. Springer, 2016, pp. 263–279.
|
| [22] |
S. Y. Huang, X. Li, Z. F. Zhang, Z. Z. He, F. Wu, W. Liu, J. H. Tang, and Y. T. Zhuang, “Deep learning driven visual path prediction from a single image,” IEEE Trans. Image Processing, vol. 25, no. 12, pp. 5892–5904, 2016. doi: 10.1109/TIP.2016.2613686
|
| [23] |
E. Principi, D. Rossetti, S. Squartini, and F. Piazza, “Unsupervised electric motor fault detection by using deep autoencoders,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 2, pp. 441–451, 2019. doi: 10.1109/JAS.2019.1911393
|
| [24] |
Y. H. Wu, M. Schuster, Z. F. Chen, Q. V. Le, M. Norouzi, W. Macherey, M. Krikun, Y. Cao, Q. Gao, K. Macherey, and et al., “Google’s neural machine translation system: Bridging the gap between human and machine translation,” arXiv preprint arXiv: 1609.08144, 2016.
|
| [25] |
D. Yu and J. Y. Li, “Recent progresses in deep learning based acoustic models,” IEEE/CAA J. Autom. Sinica, vol. 4, no. 3, pp. 396–409, 2017. doi: 10.1109/JAS.2017.7510508
|
| [26] |
K. Xu, J. L. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in Proc. Int. Conf. Machine Learning. 2015, pp. 2048–2057.
|
| [27] |
D. Quang and X. H. Xie, “DanQ: A hybrid convolutional and recurrent deep neural network for quantifying the function of DNA sequences,” Nucleic Acids Research, vol. 44, no. 11, pp. e107-1–e107-6, 2016. doi: 10.1093/nar/gkw226
|
| [28] |
J. W. Liang, L. Jiang, J. C. Niebles, A. G. Hauptmann, and F. F. Li, “Peeking into the future: Predicting future person activities and locations in videos,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, 2019, pp. 5725–5734.
|
| [29] |
J. W. Liang, L. Jiang, L. L. Cao, L. J. Li, and A. Hauptmann, “Focal visual-text attention for visual question answering,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, 2018, pp. 6135–6143.
|
| [30] |
Y. Y. Xu, Z. X. Piao, and S. H. Gao, “Encoding crowd interaction with deep neural network for pedestrian trajectory prediction,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, 2018, pp. 5275–5284.
|
| [31] |
H. Su, Y. P. Dong, J. Zhu, H. B. Ling, and B. Zhang, “Crowd scene understanding with coherent recurrent neural networks,” in Proc. 25th Int. Joint Conf. Artificial Intelligence, vol. 1, pp. 3469–3476, 2016.
|
| [32] |
H. Su, J. Zhu, Y. P. Dong, and B. Zhang, “Forecast the plausible paths in crowd scenes,” in Proc. 26th Int. Joint Conf. Artificial Intelligence, vol. 1, pp. 2772–2778, 2017.
|
| [33] |
P. Zhang, W. L. Ouyang, P. F. Zhang, J. R. Xue, and N. N. Zheng, “SR-LSTM: State refinement for LSTM towards pedestrian trajectory prediction,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, 2019, pp. 12085–12094.
|
| [34] |
A. Sadeghian, V. Kosaraju, A. Sadeghian, N. Hirose, and S. Savarese, “Sophie: An attentive gan for predicting paths compliant to social and physical constraints,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, 2019, pp. 1349–1358.
|
| [35] |
C. Wang, H. Han, X. Shang, and X. Zhao, “A new deep learning method based on unsupervised domain adaptation and re-ranking in person re-identification,” Int. J. Pattern Recognition and Artificial Intelligence, 2019.
|
| [36] |
M. Köestinger, M. Hirzer, P. Wohlhart, P. M. Roth, and H. Bischof, “Large scale metric learning from equivalence constraints,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition. IEEE, Jun. 2012.
|
| [37] |
H. Han, M. C. Zhou, and Y. Zhang, “Can virtual samples solve small sample size problem of KISSME in pedestrian re-identification of smart transportation,” IEEE Trans. Intelligent Transportation Systems, 2019.
|
| [38] |
H. Han, M. C. Zhou, X. W. Shang, W. Cao, and A. Abusorrah, “KISS+ for rapid and accurate pedestrian re-identification,” IEEE Trans. Intelligent Transportation Systems, 2020.
|
| [39] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems. 2017, pp. 5998–6008.
|
| [40] |
D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” Computer Science, arXiv preprint arXiv: 1409.0473, 2014.
|
| [41] |
S. C. Gao, M. C. Zhou, Y. R. Wang, J. J. Cheng, Y. Hanaki, and J. H. Wang, “Dendritic neuron model with effective learning algorithms for classification, approximation and prediction,” IEEE Trans. Neural Networks and Learning Systems, vol. 30, no. 2, pp. 601–614, 2019. doi: 10.1109/TNNLS.2018.2846646
|
| [42] |
J. J. Wang, and T. Kumbasar, “Parameter optimization of interval Type-2 fuzzy neural networks based on PSO and BBBC methods,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 1, pp. 247–257, 2019. doi: 10.1109/JAS.2019.1911348
|
Figures(6) / Tables(5)







 DownLoad:
DownLoad: